
 Let’s continue our series about assessing the quality of the source code of Word 1.1a, the first version of the word processor released by Microsoft in 1990.
Let’s continue our series about assessing the quality of the source code of Word 1.1a, the first version of the word processor released by Microsoft in 1990.
In the first post we saw quantitative metrics: size, complexity, level of comments and duplication. The second post was devoted to various Issues Blocker, Critical, Major and Minor.
These results suggest a strategy of development clearly oriented toward software reliability and performance, as we meet few violations of best practices in this domain. There are many more when it comes to readability and understanding the code, therefore maintainability.
I remember this analysis has been made ‘out of the box’: I have solved some problems of parsing but I have not tried to declare macros, and I worked with the default Quality Profile (set of rules) without customizing it (which I usually do). The important thing to me for this series is not to seek the maximum precision in the results because the objective is not to audit the source code for this version of Word, but to see how a simple assessment and some indicators may be useful depending on the context.
Use Cases
Context means Use Cases. When we speak of Legacy applications, the most frequent use cases will be:
- Outsourcing: transfer the maintenance of the application to a new team, an outsourcer, usually in order to reduce maintenance costs.
- Refactoring: the technical debt for this application has grown to such an extent that any modification of the source code means a disproportionately high cost of change. A refactoring is necessary to reduce the interests on the debt.
- Re-engineering: refactoring often means rethinking the design. Why not take this as an opportunity to rewrite this application in another language, newer and less difficult to maintain?
- Withdrawal: should we retire this application? This is a question that frequently arises for Legacy application, especially in the Cobol world. If it ‘s cheaper to replace it with an enterprise software, then quit it.
I will now place us in a very specific context: you have decided to buy Microsoft. Yes I know, it’s a little hard to imagine, but make an effort. Your mission – should you accept it – is to recommend a strategy for this version of Word:
- Outsourcing: what would it cost to transfer the knowledge of this application to another R&D team?
- Refactoring: what would be the cost of resolving existing defects (including a new design), for the current team? Or for a new team after a phase of knowledge transfer (case 1 + 2)?
- Reengineering: rewrite this application with a new language, such as C++ (the most logical). By the same team or a new team again (case 1 + 3).
- Decommissionning. This decision is for the management. We will not replace the application by an enterprise software, but if the costs to maintain it exceed the gains that can be expected, the application is allowed to die a natural death, with a small team to fix the most critical bugs but without any evolution.
To assess the costs of these different strategies, I had a look to the various data and information available in my dashboard, and thought which to take into account for each case.
Starting with the estimated cost of knowledge transfer for this Legacy application. What makes that a program or a function will be more or less difficult to understand?
- Its size: the longer a program, the longer it requires time to know what it does.
- Its complexity: the more conditional statements – such as a simple if … else, or multiple conditions (switch) – and loops, the harder it is to understand the flow of statements.
- Its structure: the more a program has nested code blocks, goto, break and other instructions that induce non-linear reading of the code, the more complicated are the algorithms.
I first had a look on the data about Complexity.
Complexity
Functions
We have seen in the first post that this application had functions and files with a high number of Cyclomatic Complexity points. In fact, the breakdown is as follows:
Table 1 – Cyclomatic Complexity of functions in the application Word Opus 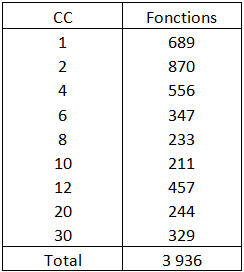
We can count 689 functions with a Cyclomatic Complexity equal to 1, then 870 functions with a CC equal to 2 and less than 4, etc.
It is considered that the optimal distribution of Cyclomatic Complexity of a C application is as follows:
- Functions with CC < 4 – Low complexity: 52 % of the total number of functions in the application.
- Functions with CC > 4 and < 10 – Moderate complexity: 25%.
- Functions with CC > 10 and < 20 – High complexity: 15%.
- Functions with CC > 20 – Very high complexity: 8%.
If we calculate the distribution of complexity in our Word application on the basis of the Table 1, we obtain the following table:
Table 2 – Distribution of the complexity in the application Word Opus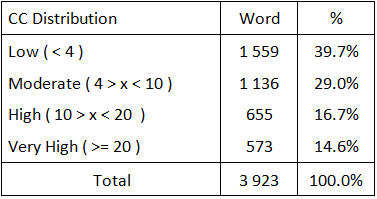
The following figure shows the distribution curve of the Cyclomatic Complexity in Word, compared to the ideal curve.
Figure 1 – Distribution curve of the complexity (Functions) 
We can see that the proportion of functions of medium or high complexity is pretty correct:
- 29% of ‘Moderate’ in Word against 25% ideally.
- 16.7% of ‘High’ in Word against 15% ideally.
However, we don’t have enough less complex functions: 39.7% of ‘Low’ instead of 52%. And the level of ‘Very high’ is too high: 14.6 % against 8% ideally. This should affect the costs of knowledge transfer and reengineering of this application.
I then focused on the most complex functions using the following metric that gives us the functions above 20 CC points.
![]() Note that we have identified 573 functions with a CC higher or equal to 20, which means that we have 34 functions (573-539) to exactly 20 points.
Note that we have identified 573 functions with a CC higher or equal to 20, which means that we have 34 functions (573-539) to exactly 20 points.
These 539 functions represent a Cyclomatic Complexity of 24 667 points, more than half of the total CC of the application (43 846, as seen in seen in the first post of this series) and some functions are extremely complex:
Table 3 – Distribution of the most complex functions

We count:
- 6 functions beyond 200 CC points (the largest even reaches 355 points), for a total of 1 513 CC points. So the 1% of these 539 complex functions represent 6% of the CC of all these functions (1 513 / 24 667).
- 30 functions between 100 and 200 CC points for a total of 3 921 points, or 5.6% of the 539 complex functions and 15.9% of the overall CC.
So in summary, 36 functions beyond 20 CC points embark 22% of the overall complexity of these 539 functions.
At the application level, these 36 functions are 0.9 % of the existing 3 936 functions and represent 12.4% of the total Cyclomatic Complexity (43 846 points).
Needless to say that we will pay particular attention to these objects, when we will discuss our action plan, whether for knowledge transfer, refactoring or re-engineering.
We will continue this article in the next post by performing the same work about file complexity.
This post is also available in Leer este articulo en castellano and Lire cet article en français.