
 We have this legacy C application, the first version of Word published by Microsoft in 1990, for which we propose to estimate the cost of different strategies: refactoring or reengineering, by the same team of developers or by another team and therefore with a knowledge transfer.
We have this legacy C application, the first version of Word published by Microsoft in 1990, for which we propose to estimate the cost of different strategies: refactoring or reengineering, by the same team of developers or by another team and therefore with a knowledge transfer.
After analyzing the source code of this application, we were able to identify the most complex components (programs and functions) and / or with a large size.
Today we will see if these programs also involve violations of best programming practices that may adversely affect the readability and understanding of the code, with the impact that you can imagine on the costs of our different strategies.
Switch case
A ‘switch’ is, as you probably know, a statement that allows to test different cases or multiple conditions. Obviously, the longer the processing of each case and complex, the longer the whole instruction – sometimes more than one page – and the more difficult to understand.
The following rule identifies the number of ‘switch case’ with more than 5 lines.
![]() I had a look again to the distribution of the violations to this good practice, according to the size of the ‘switch case’. Below 20 lines, a few minutes are sufficient to understand or correct this defect. Beyond 100 lines, the understanding of the different cases and of the whole algorithm becomes more difficult.
I had a look again to the distribution of the violations to this good practice, according to the size of the ‘switch case’. Below 20 lines, a few minutes are sufficient to understand or correct this defect. Beyond 100 lines, the understanding of the different cases and of the whole algorithm becomes more difficult.
Table 8 – Distribution of ‘switch case’ according to their size
 19 ‘switch case’ have more than 100 lines. I wanted to cross these ones with the most complex functions. You remember that in the first post of this series, we identified 30 functions with more than 100 CC (Cyclomatic Complexity) and 6 above 200 CC. In the second post, we crossed these 36 functions with the more complex programs, displaying the results with a color code:
19 ‘switch case’ have more than 100 lines. I wanted to cross these ones with the most complex functions. You remember that in the first post of this series, we identified 30 functions with more than 100 CC (Cyclomatic Complexity) and 6 above 200 CC. In the second post, we crossed these 36 functions with the more complex programs, displaying the results with a color code:
- Dark orange for functions with more than 200 CC programs in programs of more than 300 CC. Two of these files appear in the table below: ‘RTFOUT.C’ and ‘formula.c’.
- Light orange for the program ‘print.c’ with more than 400 CC and at least one function over 100 CC.
- Yellow for the program ‘RTFIN.c’ with more than 300 CC and at least one function over over 100 CC.
- White for the programs ‘Wordtech\tableins.c’ and ‘rtftrans.c’ with more than 200 CC and at least one function over 100 CC.
Table 9 – Longest ‘switch case’ in most complex functions
 This table shows that the majority (10 of 16) of the ‘switch case’ of significant size are in functions identified as very complex. The column ‘Line Switch’ shows the line of code where the ‘switch case’ begins. I also know where starts the function (‘Line Fn’) and its size in lines of code (‘Fn Size’), which allows me to calculate where it ends (‘End Fn’) and thus check if the ‘switch case’ is within it (‘In’).
This table shows that the majority (10 of 16) of the ‘switch case’ of significant size are in functions identified as very complex. The column ‘Line Switch’ shows the line of code where the ‘switch case’ begins. I also know where starts the function (‘Line Fn’) and its size in lines of code (‘Fn Size’), which allows me to calculate where it ends (‘End Fn’) and thus check if the ‘switch case’ is within it (‘In’).
For example:
- The file ‘RTFOUT.C’ is a program with more than 300 points of CC (dark orange) with a function of 355 CC including 2 ‘switch case’ of respectively 296 and 181 lines of code.
- The file ‘formula.c’ is also a program with more than 300 CC (dark orange) and a function of 234 CC and 3 ‘switch case’ of 126, 105 and 183 lines of code.
- Etc.
The existence of long structures of code difficult to understand, such as the ‘switch case’ is an aggravating factor of the cost of knowledge transfer for these programs and very complex functions.
Number of parameters
Another rule I wanted to check: functions with a high number of parameters.
![]() 43 functions have more than 7 parameters. This number is not very high when compared with the complexity of certain functions or their size in number of lines.
43 functions have more than 7 parameters. This number is not very high when compared with the complexity of certain functions or their size in number of lines.
Table 9 – Complex functions with a high number of parameters
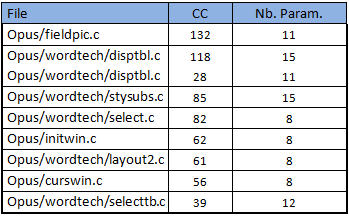 The previous table shows that these functions with a high number of parameters are not among the most complex. At least we will not have to worry because of this bad practice.
The previous table shows that these functions with a high number of parameters are not among the most complex. At least we will not have to worry because of this bad practice.
Goto
As we all know, a ‘goto’ statement is a jump to another portion of code, which breaks the continuity of the process. This statement has become the symbol of the ‘spaghetti’ code, difficult to read and maintain.
We can find a very high number of ‘goto’ in the application.
![]() In fact, a glance at the code shows that this practice is widespread throughout the application. For example, error handling is not done by calling a specific function, but with a ‘goto’ to the corresponding portion of code, sometimes even in an external library.
In fact, a glance at the code shows that this practice is widespread throughout the application. For example, error handling is not done by calling a specific function, but with a ‘goto’ to the corresponding portion of code, sometimes even in an external library.
The following table shows the distribution of ‘goto’ in the most complex programs, over 300 points of CC.
Table 11 – Distribution of Goto in the most complex programs ( > 300 CC)

1 383 ‘goto’, or 54% of their total number (2 541) are found in programs with high or extremely high Cyclomatic Complexity.
You remember that in the second post of this series, we have listed the files with a high overall complexity and which included at least a very complex function.
Table 9 – Complex files with a high number of Goto
 We can find, with a high number of ‘goto’:
We can find, with a high number of ‘goto’:
- 2 files with more than 400 CC and at least 1 function over 200 CC and 1 function over 100 CC (in red below), and also 87 and 32 ‘goto’ respectively.
- 7 files with more than 400 CC and at least 1 function over 100 CC (orange).
We have a total of:
- 142 ‘goto’ in two programs with more than 700 CC.
- 86 ‘goto’ in 3 programs with more than 600 CC.
- 200 ‘goto’ in 4 programs with more than 500 CC.
- 350 ‘goto’ in 11 programs with more than 400 CC.
Other ‘bad practices’
I did continue this work of crossing the larger and more complex programs with rules about best practice affecting readability and understanding of the code, such as ‘continue’ should not be used (MISRA C 14.5)’ or ‘If statements should not be nested too deeply’.
I will not list all results. These defects occur in (relatively) smaller numbers than those listed above, although they will also affect more complex programs and functions.
Finally, our goal is not to achieve a completely comprehensive and extremely precise study – we would need ten or more posts to do that – but to illustrate one possible approach to calculate the costs of refactoring or reengineering an application. We will see this in the next post.
This post is also available in Leer este articulo en castellano and Lire cet article en français.