
 A post as a synthesis for this series on the analysis of PL/SQL code with SonarQube.
A post as a synthesis for this series on the analysis of PL/SQL code with SonarQube.
After configuring our analysis with Jenkins, we launched it and found 17 Blockers but zero critical defects (Criticals) with the default SonarQube Quality Profile. In fact, the 5 existing Critical rules were disabled and some other rules of different criticalities too: 58 out of 132.
So we created our own Quality Profile to activate all these rules, launched again the analysis and had a look at what rules we have in the different categories of Blockers, Criticals and Majors.
The objective of this work is to build a demo on the PL/SQL code, in order to present to a client or a prospect the benefits he could get with SonarQube. For this reason, I deliberately upgraded to Criticals or even Blockers some rules regarding Reliability, Security and Performance while minimizing some other rules about Readability or Portability of the code. Just because I want to highlight the violations that coud impact the end user:
- an application that stops suddenly,
- a transaction that is not completed, with possible data corruption,
- an error in an algorithm that leads to an error of logic or calculation,
- degraded performance,
- etc.
What looks like my dashboard SonarQube now? What are the useful informations I want to focus on in a presentation? Although the dashboard SonarQube is very well organized, it’s easy not to know where to start.
I will not explain here how I make a demo, much less how I build an audit of the quality of the code. I would need more than one post, and this may be the theme for a future series. But as a synthesis of the previous posts, here’s how I do to discover a new application.
Size
When you meet someone , the first thing you notice is her size. Is he big, medium, small?
 A first widget allows me to see that here we have 16 files or database programs containing 1,569 ‘functions’ (objects or components like procedures, functions, triggers, etc.) representing 28,116 instructions (Statements).
A first widget allows me to see that here we have 16 files or database programs containing 1,569 ‘functions’ (objects or components like procedures, functions, triggers, etc.) representing 28,116 instructions (Statements).
This application has around 95 KLoc (thousand Lines of Code ) on a total of 147 Kloc: the difference is to be found in the comment lines (or blank lines, or commented-out code).
With the widget ‘Custom Measures’, I created my own view of all the size and comments information.
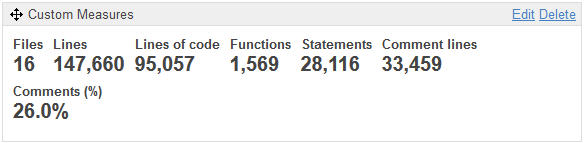
What can we deduce? We have an application of medium to large size for this technology, with a percentage of comments greater than 25%, which is correct (without predicting the quality of the documentation).
The number of lines of code per object (Functions) is less than 100, which is reasonable. We expect an average of 18 instructions (Statements) by object, so again this is not huge.
Based on these figures, one might think that a correction or a change in these components will not represent an excessive workload or cost.
Except that all this is in only 16 files, that is to say 16 scripts or programs. The granularity of each component may be correct, but we have an average of 6,000 lines of code per file, which is huge, and you can imagine that this will weigh on the maintainability of the programs.
Add or edit code into 100 lines of PL/SQL instructions is relatively easy. But when you need to look for these 100 lines, or to search the code of all other components that will be impacted by this change in a program of 6,000 lines of code, it will take time and the risk to introduce errors – bugs – during this correction or this evolution will also be high.
Therefore the next step in the discovery and evaluation of the quality of this application is to check the granularity of its components.
Granularity of components
And this is a new widget introduced in version 4.1 of SonarQube that will bring us invaluable help.
The Project File Bublle Chart shows the distribution of different files on two axis: the number of Lines of Code on the horizontal axis X, and the number of violations of good programming practices on the vertical axis Y. Note that I chose a logarithmic scale for this last one. The size of each bubble represents the technical debt in number of days for each component. All this is configurable.

Pointing to a bubble, we can display its different characteristics. On the left, the program ‘CreatePackage1.sql’ contains 6,119 lines of code, more than 4,000 defects and a technical debt of 228 days.
The script ‘create_tables.sql ‘ in the middle of the chart, contains 2.5 times more lines of code (16,810 Loc) but only 400 defects.
And in the upper right corner, we find the file ‘CreatePackageBody.sql’ with almost 58 500 lines of code, nearly 20,000 defects and more than 1,400 days of technical debt.
You will think that the project team responsible for such an application is completely mad to let grow this program at this point. In fact, not at all. Here we have a set of scripts and database programs database for a very old client-server application (over 20 years of age), with the business logic deported to the database. In that time and with the client-server languages, it was that or encode these treatments into the screens, which was not at all recommended .
But why implement all the business logic in a single file ‘CreatePackageBody.sql’? Another solution would be to distribute all these treatments into different programs. But this involves managing all the links between them, and on different versions. In that era, there were no (or very few) configuration management tools (SCM). And it is more complicated to rebuild the database with several programs that you must run in a strict order, and with the right version. It was common to see the project team working for weeks to implement corrections or evolutions, to discover finally that program A could not be executed because it was lacking the presence in the database of a component of program B, which could not be executed without a component of program A. Deadly embrace.
With a look at the other files, we can verify that these programs are responsible for creating views, triggers, etc. with few lines of code and therefore few defects. For example, the script to create the tables present very few violations for a high number of Loc, because there is no programmation there (but there might me defects on datatypes for instance).
And so this monstrous component that implements all the business logic and represents more than 60% of the application code, counterfeits all our previous observations: the size measurements seem representative of a code not too complex until the Bubble Chart shows us otherwise.
It is very likely that the maintainability and maintenance costs of this application will suffer of this. Which we will try to see in the next post.
This post is also available in Leer este articulo en castellano and Lire cet article en français.