
 Sorry to keep you waiting for the following of this series on PL/SQL code and SonarQube, but I was pretty busy between, work and my laptop who suddenly decided to abandon me, of course invoking the Murphy’s law to justify breaking down at the worst time.
Sorry to keep you waiting for the following of this series on PL/SQL code and SonarQube, but I was pretty busy between, work and my laptop who suddenly decided to abandon me, of course invoking the Murphy’s law to justify breaking down at the worst time.
In the previous posts: after configuring an analysis of PL/SQL code with SonarQube, we defined our own Quality Profile by directing Blockers and Criticals rules on robustness, performance and security. What looks like our dashboard now?
We first examined metrics of size in the previous post, to find that the average number of lines of code per object ( procedure, function , trigger, etc.) was correct.
With the new widget File Bubble Chart we discovered a single file ‘CreatePackageBody.sql’ with more than 58,000 lines, containing all the business logic in the database, which will certainly result in a high maintenance cost for this application.
Complexity and duplication
Complexity
 A glance at the Cyclomatic Complexity (CC) leads to similar results: the average complexity per object is relatively low with 6.9 points, and a maximum of 12 points. Now again, the complexity per file exceeds 600 points. We have a total of just over 10,000 points of CC throughout the application, which is not very high.
A glance at the Cyclomatic Complexity (CC) leads to similar results: the average complexity per object is relatively low with 6.9 points, and a maximum of 12 points. Now again, the complexity per file exceeds 600 points. We have a total of just over 10,000 points of CC throughout the application, which is not very high.
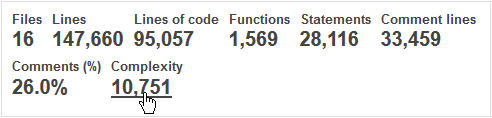
The effort to test this application is not very high. Let’s reming that the Cyclomatic Complexity is a measure of the number of different ‘paths’ in an application. Ideally, all paths must be tested, so the CC gives us an idea of the QA effort.
It is considered that with more than 20,000 points of CC for an aplication, it is necessary to perform a specific QA, defining and writing test cases and if possible, with a special tool to automate them. In our case however, we can let the project team perform these tests internally, along the development cycle or at its end.
But as can be seen with the treemap below, that I configured to display Cyclomatic Complexity …
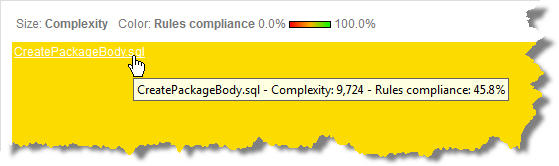
Our file ‘CreatePackageBody.sql’ represents 90% of the complexity and therefore of the application’s logic. So once again, we have figures that are correct at the application level … except that the application is contained in almost one monstrous file.
Duplications
 After evaluating the Complexity, I will look at the level of duplications, quite high. No surprise, the same monster file that implements the business logic is still leading the gang.
After evaluating the Complexity, I will look at the level of duplications, quite high. No surprise, the same monster file that implements the business logic is still leading the gang.

However, we find a large number of Copy/Paste in the other files, especially the file ‘create_tables.sql’. Since this script will create the tables in the database, it means that we have many data structures that are duplicated.
Which may indicate that the data model is not optimized. This happens often with a legacy application, because it is easier to add new tables than to evolve existing ones. But more tables means more links and joins, and thus lower performance and more complexity to maintain these data structures.
In the context of a real audit of the quality of this application, I would take the time to go through this script to verify this hypothesis and find some examples that can support a recommendation to plan a refactoring of these data structures.
For example, I count 687 ‘CREATE TABLE’ in this file, so there are 687 tables in total (not counting the views). 8,963 duplicate lines in this script means an average of 13 lines, 13 fields similar in each table. It makes sense to have some ‘key’ fields duplicated in order to perform joins, but maybe not so much.
Risky components
After watching the quantitative metrics, we already have a lot of information regarding this application, certainly more than did usually know the project team or the stakeholders and the IT managers.
The second part of a quality assessment is to identify the main threats, and this requires the identification of the riskiest components. We have seen in previous posts:
- 16 blockers for the rule ‘Use IS NULL and IS NOT NULL instead of direct NULL comparisons’, and we have seen they were duplicated many times: someone in the team probably needs to be reminded about this rule.
- 2 ‘Calling COMMIT or ROLLBACK from within a trigger will lead to an ORA-04092 exception’. And 1 ‘Do not declare a variable more than once in a given scope (PLS-00371)’: probably some mistakes due to the lack of attention, perfection is not of this world. In all cases, to be corrected immediately because of the high risk incurred to the users.
After upgrading some Major rules to Critical, we how have:
- 320 ‘Sensitive SYS owned functions should not be used’, including 270 in the file ‘CreatePackageBody.sql’: this is the problem with doing Copy/Paste, this means duplicating defects critical for the security of the application.
- A number of critical defects, corresponding to Major rules we ‘ve put in Critical:

Most of these rules impact the performance or the reliability of the application, thus pose a risk to the end user. A refactoring is recommended in order to correct these flaws in the application, especially if the user satisfaction is an important goal for our IT department. But at what cost?
This is what we will see in the next post, with the SQALE plugin for Technical Debt.
This post is also available in Leer este articulo en castellano and Lire cet article en français.