
 Un post de síntesis, para esta serie sobre el análisis de código PL / SQL con SonarQube.
Un post de síntesis, para esta serie sobre el análisis de código PL / SQL con SonarQube.
Después de configurar nuestro análisis con Jenkins, lo lanzamos y encontramos 17 defectos bloqueantes (Blockers), pero ninguna falta crítica (Criticals) con el perfil de calidad de SonarQube. De hecho, las 5 reglas Criticals eran desactivadas y también algunas otras normas de diferentes criticidades: 58 en un total de 132.
Así que hemos creado nuestro propio Quality Profile para activar todas estas reglas, ejecutado de nuevo un análisis y examinado las reglas que tenemos en las diferentes categorías Blockers, Criticals y Majors.
El objetivo de este trabajo es para mí construir una demo con código PL/SQL para presentar a un cliente los beneficios que se pueden conseguir con SonarQube. Por esta razón, yo decidí subir en Criticals o incluso en Blockers algunas reglas sobre la robustez, la seguridad y el rendimiento, y reducir las normas de legibilidad o de portabilidad del código. Sólo porque quiero destacar las violaciónes que pueden impactar al usuario final:
- una aplicación que se detiene de repente,
- una transacción que no se ha completado, con una posible corrupción de datos,
- un error en un algoritmo que lleva a un error de lógica o de cálculo,
- un rendimiento menor,
- etc.
¿A que parece ahora mi dashboard SonarQube? ¿Cuáles son las informaciones útiles que puedo enseñar en una presentación? Aunque el cuadro de mando SonarQube está muy bien organizado, es fácil no saber por dónde empezar.
No voy a explicar aquí cómo hacer una demo, y mucho menos cómo voy a construir una auditoría de la calidad del código. Se necesitaría más de un post, y probablemente será el tema de una otra serie en el futuro. Pero en modo de síntesis de los articulos anteriores de esta serie, voy a presentar lo que hago para cualificar una nueva aplicación.
El tamaño
Cuando encuentras a una persona, la primera cosa que se puede observar, es su talla. ¿Es grande, media, pequeña?
 Un primero widget me permite ver que tenemos aquí 16 ficheros o programas de base de datos, que contienen 1 569 ‘functions’ (objetos, componentes de tipo procedimiento, función, trigger, etc.) representando 28 116 instrucciones (statements).
Un primero widget me permite ver que tenemos aquí 16 ficheros o programas de base de datos, que contienen 1 569 ‘functions’ (objetos, componentes de tipo procedimiento, función, trigger, etc.) representando 28 116 instrucciones (statements).
Esta aplicación cuento con un poco más de 95 KLoc (milles de Lines of Code) en un total de 147 KLoc : la diferencia está en las líneas de comentario (o las líneas blancas, o de código en comentario).
Con el widget ‘Custom Measures’, me he customizado mi propio ‘panel’ para ver todas las informaciones de tamaño y de comentario.
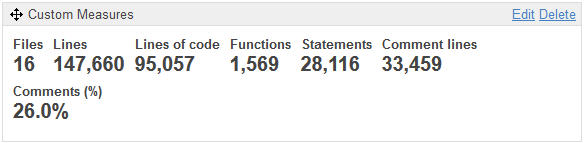
¿Qué podemos deducir ?
Tenemos una aplicación de tamaño entre medo y grande para esta tecnología PL/SQL, con un porcentage de más del 25%, pues correcto (sin llevar a augurar de su calidad).
El número medio de líneas de código por objeto (Funciones ) es inferior a 100: de nuevo, es acceptable. Contamos un promedio de 18 instrucciones (Statements) por objeto, así que de nuevo no es enorme.
Basandonos en estas cifras, se podría pensar que una corrección o un cambio en estos componentes no sería una carga excesiva.
Excepto que todo este código se encuentra en tan sólo 16 archivos, es decir, 16 scripts o programas de base de datos. La granularidad de cada componente puede ser correcta, pero un promedio de 6 000 líneas de código por archivo es enorme, y podemos imaginar que esto va a impactar en la capacidad de mantenimiento.
Añadir o editar código en un componente PL/SQL de 100 líneas es relativamente fácil. Pero cuando tienes que buscar estas 100 líneas o el código de todos los demás componentes que se verán afectados por este cambio, en un programa de 6 000 líneas de código, vas a necesitar tiempo y el riesgo de introducir un error durante esta corrección o esta evolución también será alto.
Por lo tanto, el siguiente paso en el descubrimiento y la evaluación de la calidad de esta aplicación consiste en comprobar la granularidad de sus componentes.
Granularidad de los componentes
En esto, un nuevo widget introducido en la versión 4.1 de SonarQube representa un gran valor. El Project File Bublle Chart muestra la distribución de los diferentes archivos en dos ejes: el número de líneas de Loc en el eje horizontal X, y el número de violaciónes de las buenas prácticas de programación en el eje vertical Y. Tengas en cuenta que he elegido una escala logarítmica para el segundo eje Y. El tamaño de cada burbuja representa la deuda técnica calculada en número de días para cada componente. Todo esto es configurable .

Apuntando a una burbuja, podemos ver sus características. A la izquierda, el program ‘CreatePackage1.sql’ contiene 6 119 líneas de código, más de 4 000 defectos y una deuda técnica de 228 días.
El script ‘Create_Tables.sql’ en el medio del gráfico, contiene 2,5 veces más de líneas de código (16 810 Loc), pero sólo 400 defectos y entonces una deuda técnica muy baja (8 días).
Y en la parte superior derecha de este gráfico, nos encontramos con el archivo ‘CreatePackageBody.sql’ con casi 58 500 líneas de código, cerca de 20.000 defectos y más de 1 400 días de deuda técnica.
Se puede pensar que el equipo del proyecto responsable de esta aplicación es completamente irresponsable por dejar crecer este programa hasta este punto. De hecho, en absoluto. Tenemos aquí un conjunto de scripts y programas de base de datos para una aplicación cliente-servidor muy antigua (más de 20 años de edad ), con los tratamientos de lógica de aplicación deportados en la base de datos. Era eso o codificar estos tratamientos en las pantallas, con los lenguajes de aquella época, lo que no era del todo recomendable.
Pero ¿por qué implementar toda la lógica de negocio en un único archivo? Otra solución sería la de distribuir todos estos tratamientos en diferentes programas, pero eso complica la gestión de todos los enlaces entre ellos, y en diferentes versiones. En estos tiempos, no existían herramientas de gestión de configuración (SCM). También es más complicado reconstruir la base de datos con varios programas que se deben ejecutar en un orden estricto, con las diferentes versiones correctas. Era frecuente ver el equipo de proyecto trabajando durantes semanas en cambiar los procedimientos, para descubrir que no se podia lanzar el programa A porque se necesitaba la presencia en la base de datos de un componente del programa B, y este no se podía tampoco ejecutar sin que existe ya un componente del programa A. Doble enlace mortal.
Una revisión rapida de los otros archivos nos permite verificar que estos programas son responsables de la creación de vistas (Views), triggers, etc. y con pocas líneas de código y entonces pocos defectos. Por ejemplo, el script de creación de tablas presenta muy pocas violaciónes en un alto número de Loc porque no hay tratamientos.
Las medidas de tamaño parecían indicar un código no demasiado complejo hasta que el Bubble Chart nos indica todo lo contrario: más del 60 % del código de la aplicación se encuentra en un componente monstruoso con todos los tratamientos de lógica de aplicación.
Es muy probable que los costes de mantenimiento de esta aplicación se verán afectados por eso. Lo comprobaremos en el próximo post.
Esta entrada está disponible también en Lire cet article en français y Read that post in english.