
 Lo siento por el tiempo pasado desde el último post de esta serie sobre PL/SQL y SonarQube, pero estaba muy ocupado entre viajes, el trabajo y mi laptop que decidió abandonarme, por supuesto invocando la ley de Murphy para justificar fallar en el peor momento.
Lo siento por el tiempo pasado desde el último post de esta serie sobre PL/SQL y SonarQube, pero estaba muy ocupado entre viajes, el trabajo y mi laptop que decidió abandonarme, por supuesto invocando la ley de Murphy para justificar fallar en el peor momento.
En los posts anteriores: después de configurar un análisis de código PL/SQL con SonarQube, hemos elaboraro nuestro propio Quality Profile con una orientación a la robustez, el rendimiento y la seguridad en las reglas Blockers y Criticals.
¿A que parece ahora nuestro dashboard SonarQube?
Hemos examinado en el post anterior las métricas de tamaño y no dimos cuenta que el número medio de líneas de código por objeto (procedimiento, función, trigger, etc. ) no estaba mal.
Con el nuevo widget File Bubble Chart, descubrimos más de 58.000 líneas de código en un único archivo ‘CreatePackageBody.sql’, con toda la lógica de negocio implementada en la base de datos, lo que sin duda resultará en un coste de mantenimiento alto para esta aplicación.
Complejidad y duplicación
Complejidad
 Si echamos un ojos a la Complejidad Ciclomática (CC), encontramos resultados similares: la complejidad promedio por objeto es relativamente baja con 6.9 puntos de CC, y un máximo de 12 puntos. Pero la complejidad por archivo supera los 600 puntos, y tenemos un total de poco más de 10.000 puntos de CC en toda la aplicación, lo cual no es muy alto.
Si echamos un ojos a la Complejidad Ciclomática (CC), encontramos resultados similares: la complejidad promedio por objeto es relativamente baja con 6.9 puntos de CC, y un máximo de 12 puntos. Pero la complejidad por archivo supera los 600 puntos, y tenemos un total de poco más de 10.000 puntos de CC en toda la aplicación, lo cual no es muy alto.
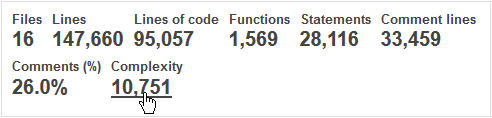
El esfuerzo de test para esta aplicación no es muy importante. Recordemos que la Complejidad Ciclomática es una medida de la cantidad de diferentes ‘caminos’ en una aplicación. Lo ideal sería hacer pruebas de todos los caminos, por lo que la CC nos da una idea del esfuerzo de pruebas.
Se considera que a partir de 20 000 puntos para una aplicación, es necesario realizar un control de calidad (QA) específico, definir y realizar casos de test y si es posible, automatizar las pruebas. En nuestro caso, podemos dejar el equipo del proyecto realizar estas pruebas de forma interna.
Pero como se puede ver con el siguiente Treemap que he configurado para mostrar la Complejidad Ciclomática …
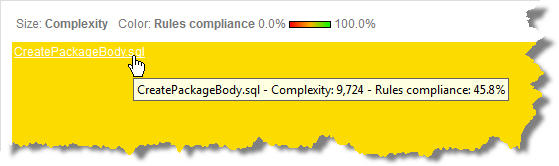
Nuestro fichero ‘CreatePackageBody.sql’ representa 90% de la complejidad y por lo tanto, de la lógica de la aplicación. Así que una vez más, tenemos cifras correctas a nivel de aplicación excepto que la casi toda la aplicación se encuentra en un solo archivo.
Duplicaciones
 Después de la complejidad, voy a interesarme en el nivel de duplicación, bastante alto. Sin sorpresa, el mismo archivo monstruoso que implementa la lógica de negocio se encuentra de nuevo en primera fila.
Después de la complejidad, voy a interesarme en el nivel de duplicación, bastante alto. Sin sorpresa, el mismo archivo monstruoso que implementa la lógica de negocio se encuentra de nuevo en primera fila.

Sin embargo, nos encontramos con un gran número de Copiado/Pegado en los otros archivos, especialmente en el fichero ‘Create_tables.sql’. Este script se encarga de crear las tablas de la base de datos, lo que significa que se duplican muchas estructuras de datos.
Eso puede indicar que el modelo de datos no está optimizado. Esto sucede por una aplicación de tipo Legacy, porque es más fácil agregar nuevas tablas que hacer evolucionar las existentes. Pero más tablas significa más enlaces, y por consiguiente un rendimiento inferior y más complejidad para mantener estas estructuras de datos.
En el contexto de una auditoría real de la calidad de esta aplicación, yo tomaría el tiempo para investigar este fichero y investigar esta hipótesis y encontrar algunos ejemplos que pueden apoyar un refactoring del ‘data model’.
Por ejemplo, hay 687 sentencias ‘CREATE TABLE’ en este archivo, y entonces 687 tablas en total (sin contar las ‘views’). 8 963 líneas duplicadas en este script significa un promedio de 13 líneas, pues 13 campos similares en cada tabla. Tiene sentido tener algunos campos ‘claves’ para llevar a cabo los ‘join’, pero tal vez no tantos.
Componentes con riesgo
Después de ver los indicadores cuantitativos, ya tenemos una gran cantidad de información con respecto a esta aplicación, sin duda más que por lo general conocen los responsables del proyecto, por no hablar de los stakeholders y los responsables de TI.
La segunda parte de una evaluación de la calidad consiste en identificar las principales amenazas, y esto requiere buscar los componentes de mayor riesgo. Hemos visto en los artículos anteriores:
- 16 bloqueadores en la regla ‘Use IS NULL and IS NOT NULL instead of direct NULL comparisons’, y además duplicados varias veces: es probable que alguien en el equipo necesita refescarse la memoria acerca de esta regla.
- 2 ‘Calling COMMIT or ROLLBACK from within a trigger will lead to an ORA-04092 exception’. Y 1 ‘Do not declare a variable more than once in a given scope (PLS-00371)’: errores por falta de atención probablemente, la perfección no es de este mundo. En todos los casos, a corregir urgentamente por el riesgo que estos defectos representan para los usuarios.
He promocionado unas reglas règles Major a la categoria Critical, y entonces ahora tenemos:
- 320 ‘Sensitive SYS owned functions should not be used’, incluyendo 270 en nuestro fiechero ‘CreatePackageBody.sql’: esto es el problema con el Copy / Paste, se duplican defectos críticos para la seguridad de las aplicaciones.
- Una serie de nuevos defectos para las reglas principales que hemos puesto en esta categoría Critical.

La mayoría de estas reglas impactan el rendimiento o la fiabilidad de la aplicación, y por lo tanto representan un riesgo para el usuario final.
Entonces se recomienda corregir estos componentes riesgosos, sobre todo si la satisfacción de los usuarios es un objetivo importante para nuestro departamento de TI. Pero ¿a qué precio?
Esto es lo que veremos en el próximo post, con el plugin SQALE de la deuda técnica.
Esta entrada está disponible también en Lire cet article en français y Read that post in english.