
 Tenemos esta aplicación Legacy C, la primera versión de Word publicada por Microsoft en el año 1990, para la cual se propone cuantificar el coste de diferentes estrategias: refactorización o reingeniería, por el mismo equipo de desarrolladores o por un nuevo equipo y por tanto, con una transferencia de conocimiento.
Tenemos esta aplicación Legacy C, la primera versión de Word publicada por Microsoft en el año 1990, para la cual se propone cuantificar el coste de diferentes estrategias: refactorización o reingeniería, por el mismo equipo de desarrolladores o por un nuevo equipo y por tanto, con una transferencia de conocimiento.
Después de analizar el código fuente de esta aplicación, hemos podido identificar loscomponentes (programas y funciones) más complejos (Ciclomática Complejidad) y / o con un tamaño grande.
Hoy vamos a ver si estos programas también tienen violaciónes de buenas prácticas de programación que pueden impactar negativamente a la legibilidad y la comprensión del código, con las consecuencias que podemos imaginar sobre los costes de nuestros diferentes estrategias.
Switch case
Un ‘switch’ es, como probablemente lo sabes, una instrucción que permite probar diferentes casos (‘cases’) o múltiples condiciones. Obviamente, cuanto más largo y complejo el tratamiento de cada caso, más larga será toda la instrucción – a veces por encima de una página – y más difícil de entender.
La siguiente regla identifica el número de ‘switch cases’ con más de 5 líneas.
![]() Me interesé de nuevo en la distribución de esta buena práctica en relación con el tamaño del ‘switch case’. Debajo de 20 líneas, pocos minutos son suficientes para entender o corregir este defecto. Más allá de 100 líneas, la comprensión del algoritmo y de los diferentes casos se vuelve más difícil.
Me interesé de nuevo en la distribución de esta buena práctica en relación con el tamaño del ‘switch case’. Debajo de 20 líneas, pocos minutos son suficientes para entender o corregir este defecto. Más allá de 100 líneas, la comprensión del algoritmo y de los diferentes casos se vuelve más difícil.
Tabla 8 – Distribución de los ‘switch cases’ con arreglo a su tamaño
 19 ‘switch cases’ tienen más de 100 líneas. Quería cruzarlos con las funciones más complejas. ¿Te acuerdas de que en el primer post de esta serie, hemos identificado 30 funciones con más de 100 CC (Complejidad Ciclomática) y 6 con más de 200 CC. En el segundo post, hemos cruzado estas 36 funciones con los programas más complejos, con un código de color:
19 ‘switch cases’ tienen más de 100 líneas. Quería cruzarlos con las funciones más complejas. ¿Te acuerdas de que en el primer post de esta serie, hemos identificado 30 funciones con más de 100 CC (Complejidad Ciclomática) y 6 con más de 200 CC. En el segundo post, hemos cruzado estas 36 funciones con los programas más complejos, con un código de color:
- NaranJa oscuro para las funciones con más de 200 CC en programas de más de 300 CC: dos de estos archivos aparecen en la siguiente tabla: ‘RTFOUT.C’ y ‘formula.c.
- Naranja claro para el programa ‘print.c’ con más de 400 CC y al menos una función de más de 100 CC.
- Amarillo para el programa ‘RTFIN.c’ con más de 300 y al menos una función de más de 100 CC.
- Blanco para los programas ‘wordtech\tableins.c’ y ‘rtftrans.c’ con más de 200 CC y al menos una función de más de 100 CC.
Tabla 9 – Los ‘switch cases’ más largos en las funciones más complejas
 Esta tabla muestra que la mayoría (10 de 16) de los ‘switch case’ con un tamaño significativo se encuentran en funciones identificadas como muy complejas. La columna ‘Switch Line’ muestra la línea de código donde comienza el ‘switch case’. También conozco la línea donde se inicia la función (‘Line Fn’) y el tamaño de esta misma en número de líneas (‘Fn Size’), lo que me permite calcular la línea de código donde termina la función (‘End Fn’) y así comprobar si el ‘switch case’ está dentro de ella (‘In’).
Esta tabla muestra que la mayoría (10 de 16) de los ‘switch case’ con un tamaño significativo se encuentran en funciones identificadas como muy complejas. La columna ‘Switch Line’ muestra la línea de código donde comienza el ‘switch case’. También conozco la línea donde se inicia la función (‘Line Fn’) y el tamaño de esta misma en número de líneas (‘Fn Size’), lo que me permite calcular la línea de código donde termina la función (‘End Fn’) y así comprobar si el ‘switch case’ está dentro de ella (‘In’).
Por ejemplo:
- El archivo ‘RTFOUT.C’ es un programa de más de 300 puntos de CC (naranja oscuro) con una función de 355 CC, en el que hay 2 ‘switch case’, con respectivamente 296 y 181 líneas de código.
- El archivo ‘formula.c’ es también un programa de más de 300 CC (naranja oscuro) con una función de 234 CC y 3 ‘switch case’ de 126, 105 y 183 líneas de código.
- Etc.
La existencia de estructuras de código largas y difíciles de entender, como el ‘switch case’ es un factor agravante de los costes de la transferencia de conocimientos para estos programas y funciones ya muy complejos.
Número de parámetros
Otra regla que deseé comprobar: funciones con un alto número de parámetros.
![]() 43 funciones tienen más de 7 parámetros. Este número no es muy elevado si se compara con la complejidad de las funciones o de su tamaño en número de líneas.
43 funciones tienen más de 7 parámetros. Este número no es muy elevado si se compara con la complejidad de las funciones o de su tamaño en número de líneas.
Tabla 9 – funciones complejas con un alto número de parámetros
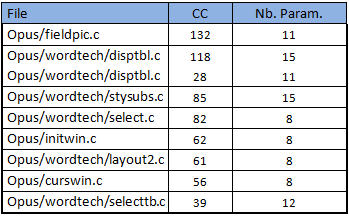 Le tabla anterior muestra que estas funciones no se encuentran entre las más complejas. Al menos no tendremos que preocuparnos por esto.
Le tabla anterior muestra que estas funciones no se encuentran entre las más complejas. Al menos no tendremos que preocuparnos por esto.
Goto
Como todos sabemos, un ‘goto’ es un ‘salto’ a otra parte del código, que rompe la continuidad del flujo de tratamientos. Esta instrucción se ha convertido en el símbolo del código ‘spaghetti’, difícil de leer y mantener.
Nos encontramos con un número muy alto en la aplicación.
![]() De hecho, un vistazo al código nos permite comprobar que esta práctica está muy extendida en toda la aplicación. Por ejemplo, el tratamiento de errores no se hace llamando a una función específica, pero con un ‘goto’ a la porción correspondiente de código, a veces incluso en una biblioteca externa.
De hecho, un vistazo al código nos permite comprobar que esta práctica está muy extendida en toda la aplicación. Por ejemplo, el tratamiento de errores no se hace llamando a una función específica, pero con un ‘goto’ a la porción correspondiente de código, a veces incluso en una biblioteca externa.
La siguiente tabla muestra la distribución de ‘goto’ en los programas más complejos, superando los 300 puntos de CC.
Tabla 11 – Distribución de Goto en los programas más complejos ( > 300 CC)

1 383 ‘goto’, es decir 54% del número total (2 541) se encuentran en los programas con un nivel alto o altísimo de Complejidad Ciclomática.
Te recuerdás que en el segundo episodio de esta serie, hemos hecho una lista de los archivos con una alta complejidad y que incluyen por lo menos una función muy compleja.
Tabla 9 – Archivos complejos con un alto número de Goto
 Encontramos, con un número elevado de ‘Goto’:
Encontramos, con un número elevado de ‘Goto’:
- 2 archivos con más de 400 CC y al menos una función de más de 200 CC + 1 función de más de 100 cc (en rojo abajo), contando también con 87 y 32 ‘goto’.
- 7 archivos con más de 400 CC con al menos una función de más del 100 CC (naranja).
Tenemos un total de:
- 142 ‘goto’ en dos programas con más de 700 CC.
- 86 ‘goto’ en 3 programas con más de 600 CC.
- 200 ‘goto’ en 4 programas con más de 500 CC.
- 350 ‘goto’ en 11 programas con más de 400 CC.
Otras ‘malas prácticas’
Continué este trabajo de busqueda de convergencias entre los programas más grandes y las funciones más complejas con las violaciónes a las mejores prácticas que afectan a la legibilidad y la comprensión del código, como ‘continue’ should not be used (MISRA C 14.5)’ ou ‘If statements should not be nested too deeply’.
No voy a enumerar todos los resultados. Estos defectos se producen en números (relativamente) memos elevados que los anteriores, pero igualmente afectarán los programas y funciones más complejos.
Por último, nuestro objetivo no es realizar un estudio totalmente exhaustivo y extremadamente preciso – necesitaría diez o más articulos de este blog – pero de ilustrar un posible enfoque para calcular los costes de refactorización o de reingeniería de una aplicación. Vamos a tratar esta estimación en el próximo post.
Esta entrada está disponible también en Lire cet article en français y Read that post in english.