
 En nuestro post anterior, hemos hablado de la définición de Michael Feathers (en su libro « Working Effectively with Legacy Code ») explicando que la ausencia de pruebas unitarias es el factor determinante de una aplicación Legacy. El propone el concepto de prueba de caracterización para entender el comportamiento de la aplicación, es decir, lo que realmente hace, sin tratar de descubrir a través del código que se supone que debe hacer.
En nuestro post anterior, hemos hablado de la définición de Michael Feathers (en su libro « Working Effectively with Legacy Code ») explicando que la ausencia de pruebas unitarias es el factor determinante de una aplicación Legacy. El propone el concepto de prueba de caracterización para entender el comportamiento de la aplicación, es decir, lo que realmente hace, sin tratar de descubrir a través del código que se supone que debe hacer.
Pero ¿qué pasa cuando nuestra aplicación Legacy no tiene nada de pruebas unitarias? La respuesta a uno de nuestros tres escenarios – el plan de transferencia de la aplicación a otro equipo – puede hacerse escribiendo estas pruebas? ¿Es posible facilitar la transferencia de conocimientos con pruebas unitarias?
Las pruebas de caracterización
Michael Feathers recomienda en su libro hacer pruebas diseñadas no sólo para verificar que el código es correcto, pero también y sobre todo para caracterizar su comportamiento, es decir, para averiguar lo que realmente hace este código. Las ventajas son:
- Permitir, sino la transferencia, pero al menos facilitar la adquisición del conocimiento de la aplicación por un nuevo equipo.
- Desarrollar pruebas que serán válidas para nuestra futura operación de refactorización o de reingeniería puesto que el comportamiento de nuestra aplicación debe permanecer constante después de esta operación.
Michael Feathers recomienda proceder de la siguiente manera:
- Para un bloque de código a probar / documentar, escribir una prueba que sabemos que va a fallar.
- Ejecutar la prueba y registrar la repuesta esperada por el bloque de código, que corresponde con el comportamiento esperado.
- Añadir una prueba para reflejar el comportamiento correcto, es decir, que devuelve un resultado positivo.
- Repetir tantas veces como deseado para este bloque de código.
El ejemplo que utiliza Michael Feathers corresponde al lenguaje Java, y puede ser diferente para otro código Legado, especialmente para C, pero dependerá en todo caso de lo que quieres hacer, especialmente si tienes un framework de pruebas. No voy a profundizar este punto: los desarrolladores en C/C++ saben mejor que yo sobre este tema.
Ejemplo de la función RTFOUT
El método recomendado por Michael Feathers sigue siendo el mismo, sea cual sea la tecnología (C, Java, etc.) que deseamos ‘caracterizar’ y las herramientas que vamos a utilizar. Veamos un ejemplo con nuestra aplicación Word 1.1a.
Sabemos que la función más compleja, con 355 puntos de CC (Complejidad Ciclomática) cuenta 2063 LOC (Lines Of Code)!
El dashboard SonarQube me dice que esta función está en un archivo con el mismo nombre ‘Opus\RTFOUT.c’, y ella representa casi todo el código (hay otra función con 2 puntos de CC), con 1 124 instrucciones y una tasa de 17.5% de comentarios.

Las primeras 200 líneas son una acumulación de includes y variables con nombres esotéricos, sin comentarios o mal documentados:
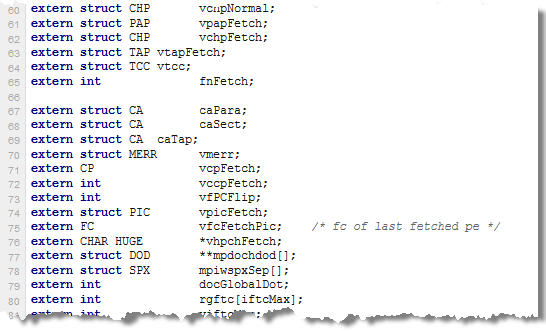 Ni siquiera sirve intentar de entender de que se trata.
Ni siquiera sirve intentar de entender de que se trata.
Sin embargo, después de unos ‘if .. else’, encuentro rápidamente el siguiente ‘switch’:
 Ahora entiendo que estamos en presencia de una función responsable de la producción del formato RTF (Rich Text Format) del texto escrito en Word, y este primer ‘switch’ especifica el tipo de fuente – Modern, Roman, Swiss, etc. – utilizado en este formato. Y la variable ‘fmc’ gestionará estos valores.
Ahora entiendo que estamos en presencia de una función responsable de la producción del formato RTF (Rich Text Format) del texto escrito en Word, y este primer ‘switch’ especifica el tipo de fuente – Modern, Roman, Swiss, etc. – utilizado en este formato. Y la variable ‘fmc’ gestionará estos valores.
Otro ‘switch’, bastante largo, gestiona las propiedades del documento, si están disponibles: título, tema, autor, etc.
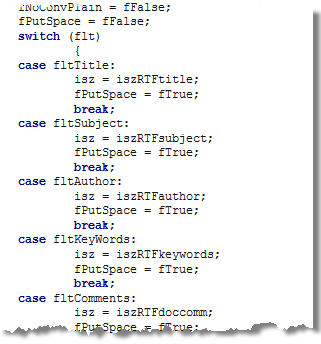 … la fecha de la última edición del documento, el número de páginas, número de palabras o de caracteres:
… la fecha de la última edición del documento, el número de páginas, número de palabras o de caracteres:

Sin embargo me doy cuenta que puedo identificar todos los bloques de código bastante simples y legibles y desarrollar pruebas de caracterización, una para cada valor posible encontrado en una estructura condicional (‘end .. if’, ‘switch’) o bucle (que requiere también una condición). En este caso, se puede escribir una o más pruebas para verificar los valores existentes o no.
Por ejemplo, voy a probar los diferentes estados de la variable ‘fmc’ con los valores que podemos encontrar en el código: ‘FF_ROMAN’, ‘FF_MODERN’ … o un valor inexistente ‘FF_WRONG’ para ver cómo reacciona la aplicación.
Del mismo modo para la variable ‘flt’ que maneja las propiedades del documento: puedo probar todo tipo de valores impossibles para ver de nuevo cómo se comporta la aplicación en este caso. ¿Qué está pasando, por ejemplo, si hago una prueba:
- Con un número de páginas igual a 999 999?
- Con caracteres especiales (@, #,!, ¿, …) en el nombre del autor?
- Con diferentes formatos para la fecha de la última actualización?
Por supuesto, unos bloques de código, como la gestión en memoria de la tabla de los marcadores (bookmarks) en un documento Word, serán demasiado complejos para que sea posible entender y probar de manera adecuada y sin ningún tipo de ayuda. Pero recuerda que el objetivo principal no es de entender lo que se supone que debe hacer la aplicación a través de su código, sino caracterizar su comportamiento.
También descubrí muy rápidamente líneas de código que se repiten antes de cada bucle o cada ‘switch’. Supongo que son variables que se inicializan antes de cada tratamiento y se actualizan durante aquellos. Tomo nota de revisar la documentación (si la hay) o pedir información al equipo actual respecto a estas variables. Si se repiten con tanta frecuencia, eso puede tener un impacto en un nuevo diseño de esta función durante una refactorización o reingeniería.
NOTA: Un problema con el lenguaje C es que ciertos objetos se externalizan (en un include o una macro). Como lo describe Michael Feathers en su libro, es muy posible modificar el código para crear y utilizar nuestro propio include con una llamada a estos componentes para comprobar rápidamente si se les llama con el número correcto de parámetros y con los tipos adecuados. Por favor, consulte su libro si tiene alguna pregunta, no voy a mencionar todas ellas en este post.
Otro problema que encontré en el código: una gran cantidad de directivas de compilador #IFNDEF o para diferentes plataformas (Mac). Por lo tanto, se deben tener en cuenta en la reingeniería.
Síntesis
La ventaja del enfoque recomendado por Michael Feathers es de investigar, no lo que la aplicación se supone que debe hacer, a través de su código – tarea larga, y a veces imposible – pero en lo que la aplicación hace realmente. Sobre todo porque la aplicación no siempre se comporta como se supone que debería hacerlo.
Podemos crear rápidamente pruebas en bloques de código con estructuras condicionales (‘if .. else’, ‘switch’) o bucle. Recuerda que cada camino o «path» en estas estructuras es una regla de lógica de negocio y por lo tanto normalmente debería estar cubierto por una prueba correspondiente.
Lo cual nos lleva a la pregunta siguiente: ¿cuántos tests de caracterización son necesarios para asegurar la transferencia de conocimientos de esta aplicación Legacy? ¿Qué cobertura de código asegurar antes de empiezar una refactorización o una reingeniería? ¿Podemos estimar el esfuerzo de pruebas que se necesitan? Esto es lo que veremos en nuestro próximo post.
Esta entrada está disponible también en Lire cet article en français y Read that post in english.