
 Microsoft ha publicado esta semana lel código fuente de Word 1.1a (1990) mediante el Computer History Museum: http://www.computerhistory.org/atchm/microsoft-word-for-windows-1-1a-source-code/.
Microsoft ha publicado esta semana lel código fuente de Word 1.1a (1990) mediante el Computer History Museum: http://www.computerhistory.org/atchm/microsoft-word-for-windows-1-1a-source-code/.
Es una de las primeras versiones de Word para Windows, de enero 1991:
http://blogs.technet.com/b/microsoft_blog/archive/2014/03/25/microsoft-makes-source-code-for-ms-dos-and-word-for-windows-available-to-public.aspx.
Tuve la idea de analizar este código fuente. Tenía curiosidad por ver los resultados, tanto desde el punto de vista cuantitativo – número de líneas de código, la complejidad, etc – como cualitativo: violaciones de buenas prácticas de programación, defectos tipo Blockers, Criticals, etc.
Además, ¿cual sería la deuda técnica para este software y cómo usarla en tal contexto? No es todos los días que se encuentra una aplicación C Legacy como esta. ¿Cuáles son los casos de uso interesantes en este contexto y la forma en que el análisis de la deuda técnica nos puede ayudar?
Veremos este último punto al final. Todavía no sé cuántos posts voy a dedicar a estos temas. En este primer artículo, voy a presentar brevemente la configuración de análisis y los primeros resultados.
Análisis
No voy a dar demasiados detalles, ya que el código fuente no está publicado bajo una licencia libre y está prohibido su uso con fines comerciales. Entiendes que no tengo ningún deseo de meterme en problemas con Microsoft por exponer en este post una empresa o sus productos. Así que me limitaré simplemente a decir que hice mi análisis con SonarQube versión 4.2 y su Plugin C/C++ versión 2.1.
 Si descargas el .zip correspondiente del código Word 1.1a, encontrarás 3 carpetas con diferentes versiones, con más o menos documentación e utilitarios. He utilizado la versión más simple, ‘Opus’, que se centra en el código fuente.
Si descargas el .zip correspondiente del código Word 1.1a, encontrarás 3 carpetas con diferentes versiones, con más o menos documentación e utilitarios. He utilizado la versión más simple, ‘Opus’, que se centra en el código fuente.
Hay varios tipos de archivos que no pueden ser analizados: ejecutables .exe por ejemplo o código Assembler. He trabajado con los ficheros .c y .h. Los directorios ‘lib’ y ‘resource’ sólo contienen .h. Otras carpetas, como la principal ‘Opus’ contienen ficheros .c y h.
No he probado a declarar macros. Esto requiere un conocimiento preciso de la aplicación, y sin un arquitecto o un miembro del equipo del proyecto, puede tomar un largo tiempo para entender cómo se estructura todo el código. Sería esencial para identificar potenciales bugs, pero no estoy buscando tal precisión en los resultados sino una evaluación global de la calidad.
Encontré algunos errores de análisis (parsing), principalmente por las declaraciones de un tipo de datos, creo para una compilación para un OS Apple (Mac). He intentado varios tipos de sintaxis de C (C89, C99 o C11), sin resultado a este nivel. Se trata esencialmente de estructuras de datos que pusé luego en comentarios, sin ningún impacto en los resultados de análisis, a excepción de que voy a perder unas pocas líneas de código en el cálculo final .
También hay archivos que no analizar, como un archivo que comienza con ‘THIS FILE IS OBSOLETE’ incluso sin que esta línea sea en comentarios, por lo que es normal que se genera un error en el analizador.
Por último, he utilizado el perfil de calidad por defecto de SonarQube, sin normas adicionales, tales como las de Cppcheck. Una vez más, nuestro objetivo no es depurar Word, pero realizar un análisis global de la calidad del código, evaluar la deuda técnica para este software y tratar de extraer algunas lecciones. Todo en el contexto de la época.
Métricas cuantitativas
Llamo métricas cuantitativas todos los datos que nos dan una idea del tamaño y la complejidad del código, el nivel de comentarios, etc. En resumen, todo lo que no se refiere a las buenas prácticas de programación.
Tamaño
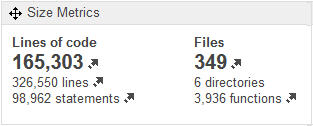 Encontramos 326.500 líneas en 349 ficheros, de los cuales 165 mil son líneas de código (KLocs ). Yo esperaba encontrar muchas más líneas de código, pero lo que es sorprendente para mí es el pequeño número de archivos. En promedio , cada archivo tiene cerca de 1 000 líneas, la mitad de código. Esto no favorece la lectura y la comprensión, sobre todo cuando se trata de un lenguaje tan complejo que el lenguaje C.
Encontramos 326.500 líneas en 349 ficheros, de los cuales 165 mil son líneas de código (KLocs ). Yo esperaba encontrar muchas más líneas de código, pero lo que es sorprendente para mí es el pequeño número de archivos. En promedio , cada archivo tiene cerca de 1 000 líneas, la mitad de código. Esto no favorece la lectura y la comprensión, sobre todo cuando se trata de un lenguaje tan complejo que el lenguaje C.
Por otra parte, si nos fijamos en la distribución de los archivos de código utilizando el gráfico Project File Bubble Chart, se puede ver a algunos bonitos monstruos, como este archivo ‘fltexp.c’, con 2 600 líneas de código y 506 ‘Issues’. Sin embargo, su deuda técnica queda limitada con sólo 23 días de refactorización estimados para corregir los defectos detectados.

Documentación
El nivel de comentarios es correcto sin ser excepcional, yo diría que en el rango inferior de lo que generalmente se puede esperar de una aplicación hoy en día, aunque de nuevo, no estamos en presencia de una aplicación de gestión, pero de un software. 
Además, el nivel de documentación es importante cuando se sabe que una aplicación puede ser subcontratada a un outsourcer, y que otros que sus autores tendrán que entender lo que hace el código, Pero no es el caso para un código mantenido por un equipo de I+D. Por último, 20% de comentarios era probablemente correcto 30 años antes, aunque parece más bien bajo en la actualidad.
Duplicaciones
Me llamó la atención el nivel mínimo de duplicación. Y a comprobar en el código, se trata esencialmente de estructuras de datos.
Recordemos que no estamos tratando aquí con un lenguaje orientado a objetos, por lo que no es posible crear clases específicas a un componente funcional. Aún así, el nivel extremadamente bajo de duplicación muestra una reutilización óptima del código existente. Probablemente esencial para una I+D que debe desarrollar y mantener softwares, pero ciertamente no es tan común en nuestros días.
Complejidad
 El nivel global de Complejidad Ciclomática (CC) es bastante alto, con 43.846 puntos de complejidad. Recordemos que por encima de 20.000 puntos, una aplicación requiere una fase específica de QA , con cuadernos de pruebas formalizadas. Con 60.000 puntos, es muy recomendable una herramienta de automatización de pruebas. No existían tales herramientas a principios de 1990, así que estoy curioso por saber más acerca de las prácticas de Microsoft en acuel momento.
El nivel global de Complejidad Ciclomática (CC) es bastante alto, con 43.846 puntos de complejidad. Recordemos que por encima de 20.000 puntos, una aplicación requiere una fase específica de QA , con cuadernos de pruebas formalizadas. Con 60.000 puntos, es muy recomendable una herramienta de automatización de pruebas. No existían tales herramientas a principios de 1990, así que estoy curioso por saber más acerca de las prácticas de Microsoft en acuel momento.
La gran mayoría de las funciones no son muy complejas, pero sin embargo varios cientos de ellas superan los 12 puntos de CC, y un gran número son por encima de 30 puntos de CC, lo que significa que son objetos complejos o muy complejos, con un alto coste de mantenimiento y un alto riesgo de introducir un defecto en caso de modificación. Por lo tanto, la fase de control de calidad debe ser aún más exigente.
Afortunadamente , hemos visto que el nivel de reutilización era muy bueno. Entonces, se pueden centrar las pruebas de regresión en los objetos más complejos que han sido modificado.
 Este alto nivel de complejidad en las funciones se confirma en los archivos, con cerca de la mitad de ellos por encima de 90 puntos de CC.
Este alto nivel de complejidad en las funciones se confirma en los archivos, con cerca de la mitad de ellos por encima de 90 puntos de CC.
He configurado el gráfico Bubble Chart para cruzar el número de líneas de código con la complejidad:

Una vez más, nos encontramos con el archivo ‘fltexp.c’ con 2 600 líneas de código y un nivel de CC de 740. Cuando yo digo que ¡este es un monstruo!
Evaluación
¿Qué podemos decir por ahora, en este momento de nuestra evaluación?
El muy bajo nivel de código duplicado me hace pensar que la elección del equipo de proyecto ha sido centrar la arquitectura de desarrollo en la máxima reutilización de funciones, y por lo tanto ser capaz de dedicar cada archivo para una función específica, con todos los objetos necesarios para la gestión de ella. Esto explica por qué algunos archivos son muy largos y gordos, tanto en tamaño como en complejidad.
Debemos recordar que la memoria era limitada en esta epoca, y el tamaño de memoria necesitado por un software era un criterio importante del rendimiento y por lo tanto de su éxito o su fracaso. Pues, prioridad en la eficiencia en este dominio, lo que significa evitar la duplicación de estructuras de datos en diferentes archivos, incluso si esto significa más archivos más pesados y más complejos.
Esto probablemente afectará la legibilidad, la comprensión y la capacidad de mantenimiento del código.
Vamos a prestar atención a estos factores en nuestro próximo post sobre los resultados cualitativos y el cumplimiento de las buenas prácticas de programación.
Esta entrada está disponible también en Lire cet article en français y Read that post in english.