
 Un post en guise de synthèse, pour cette série sur l’analyse de code PL/SQL avec SonarQube.
Un post en guise de synthèse, pour cette série sur l’analyse de code PL/SQL avec SonarQube.
Après avoir configuré notre analyse avec Jenkins, nous avons lancé celle-ci et constaté 17 infractions bloquantes (Blockers) mais zéro défaut critique (Critical) avec le Quality Profile par défaut de SonarQube. En fait, les 5 règles Critical existantes étaient désactivées, ainsi que certaines des autres règles de différentes criticités : 58 sur un total de 132.
Nous avons donc créé notre propre Quality Profile afin d’activer toutes ces règles, relancé une analyse et regarder concrètement de quelles règles nous disposions ainsi dans les différentes catégories Blockers, Criticals et Majors.
L’objectif de ce travail est de me constituer une démo sur du code PL/SQL afin de présenter à un client ou un prospect les bénéfices qu’il peut tirer de SonarQube. Pour cette raison, j’ai délibérément remonté en Criticals, voire en Blockers certaines règles qui concernent la fiabilité, la sécurité ou la performance tout en minimisant les règles en matière de lisibilité ou de portabilité du code. Tout simplement parce que je souhaite mettre en avant les violations qui vont impacter l’utilisateur final :
- une application qui s’arrête brusquement,
- une transaction qui n’est pas finalisée, avec une possible corruption de données,
- une erreur dans un algorithme qui conduit à une erreur de logique ou de calcul,
- une performance dégradée,
- etc.
A quoi ressemble maintenant mon tableau de bord SonarQube ? Quelles sont les informations utiles ou que je vais mettre en avant dans une présentation ? Même si le dashboard SonarQube est très bien organisé, il est facile de ne pas savoir par où commencer.
Je ne vais pas expliquer ici comment j’effectue une démo, encore moins comment je construis un audit de la qualité du code. Il faudrait bien plus d’un post, et ce fera probablement l’objet d’une série future. Mais en guise de synthèse des posts précédents de cette série, voici comment je procède lorsque je découvre une nouvelle application.
La taille
Lorsque vous rencontrez une personne, la première chose que vous remarquez, c’est sa taille. Est-elle grande, moyenne, petite ?
 Un premier widget me permet de voir que nous avons ici 16 fichiers ou programmes de base de données, qui contiennent 1 569 ‘fonctions’ (objets de type procédure, fonction, trigger, etc. ) représentant 28 116 instructions (statements).
Un premier widget me permet de voir que nous avons ici 16 fichiers ou programmes de base de données, qui contiennent 1 569 ‘fonctions’ (objets de type procédure, fonction, trigger, etc. ) représentant 28 116 instructions (statements).
Cette application compte environ 95 KLoc (milliers de Lines of Code) sur un total de 147 KLoc : la différence est constituée par les lignes de commentaires (ou des lignes blanches, ou du code en commentaire).
Avec le widget ‘Custom Measures’, je me suis constitué mon propre ‘panneau’ afin d’afficher ensemble ces informations de taille et de commentaires.
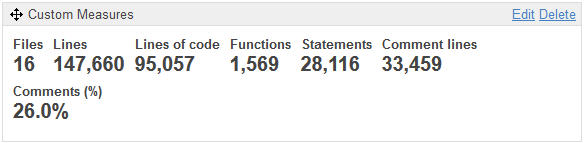
Que pouvons-nous en déduire ? Nous avons là une application de taille moyenne à importante pour cette technologie, avec un taux de commentaires supérieur à 25%, donc correct (sans présager de la qualité de ceux-ci).
Le nombre de lignes de code par objet (Functions) est inférieur à 100, donc raisonnable. Nous comptons en moyenne 18 instructions (Statements) par objet, donc là encore ce n’est pas énorme.
Sur la base de ces chiffres, on peut penser qu’une correction ou une évolution sur ces composants ne représentera pas une charge trop importante.
Sauf que tout cela tient en seulement 16 fichiers, c’est-a-dire 16 scripts ou programmes. La granularité de chaque composant est peut-être correcte, mais nous avons en moyenne 6 000 lignes de code par fichier, ce qui est donc énorme, et vous pouvez imaginer que cela va peser sur la maintenabilité de ces programmes.
Ajouter ou modifier du code dans un composant PL/SQL de 100 lignes est relativement aisé. Mais lorsque vous devez rechercher ces 100 lignes ou le code de tous les autres composants qui seront impactés par cette modification, au sein d’un programme de 6 000 lignes de code, cela va prendre du temps et le risque d’introduire une erreur – un bug – à l’occasion de cette correction ou de cette évolution sera également élevé.
Donc l’étape suivante dans la découverte et l’évaluation de la qualité de cette application consiste à vérifier la granularité de ses composants.
Granularité des composants
Et c’est là qu’un nouveau widget introduit avec la version 4.1 de SonarQube nous apporte une aide précieuse.
Le Project File Bublle Chart affiche la répartition des différents fichiers selon deux axes : le nombre de Lines of Loc sur l’axe horizontal X, et le nombre de violations aux bonnes pratiques de programmation, sur l’axe vertical Y. A noter que j’ai choisi une échelle logarithmique pour ce dernier. La taille de chaque bulle représente la dette technique en nombre de jours pour chaque composant. Tout ceci est paramétrable.

En pointant sur une bulle, nous pouvons voir s’afficher ses différentes caractéristiques. A gauche, le programme ‘CreatePackage1.sql’ contient 6 119 lignes de code, plus de 4 000 défauts et une dette technique de 228 jours.
Le script ‘Create_Tables.sql’, au milieu, contient 2,5 fois plus de lignes de code (16 810 Loc) mais seulement 400 défauts.
Et dans le coin supérieur droit de ce graphique, nous trouvons le fichier ‘CreatePackageBody.sql’ avec près de 58 500 lignes de code, prés de 20 000 défauts et plus de 1 400 jours de dette technique.
Vous allez penser que l’équipe de projet responsable d’une telle application est complètement irresponsable de laisser croître un tel programme à ce point. En fait, pas du tout. Nous avons là un ensemble de scripts et de programmes de bases de données pour une application client-serveur très ancienne (plus de 20 ans d’âge), avec les traitements de logique métier déportés au niveau de la base de données. C’était çà ou coder ces traitement dans les écrans, dans les langages de l’époque, ce qui n’était pas du tout recommandé.
Mais pourquoi implémenter toute la logique applicative dans un seul et unique fichier ‘CreatePackageBody.sql’ ? Une autre solution consisterait en répartir tous ces traitements dans différents programmes, mais cela implique de gérer tous les liens entre ceux-ci, et ce sur différentes versions. Or á l’époque, il n’y avait pas d’outils de gestion de configuration (SCM). Et puis, il est plus compliqué de reconstruire la base de données avec plusieurs programmes que vous devez exécuter en respectant un ordre précis, sans vous tromper de versions, …
Un coup d’œil sur les autres fichiers nous permettra de vérifier que ces programmes sont en charge de créer des vues, des triggers, donc avec peu de lignes de code et donc peu de défauts. Comme par exemple, le script de création des tables qui présente très peu de violations pour un nombre élevé de lignes puisqu’il n’y a pas de traitements.
Et donc ce composant monstrueux qui réunit tous les traitements, et fausse toutes les moyennes en matière de taille des composants, puisqu’il représente à lui seul plus de 60% du code de l’application. Ces mesures de taille semblaient indiquer un code pas trop complexe à faire évoluer, jusqu’à ce que le Bubble Chart nous fournisse des indications contraires.
Il est très probable que la maintenabilité et les coûts de maintenance de cette application vont en souffrir. Ce que nous vérifierons dans le prochain post.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.