
 Désolé de vous avoir fait attendre pour la suite de cette série sur le code PL/SQL et SonarQube, mais j’ai été pas mal occupé, entre voyages, travail et mon portable qui m’a lâchement abandonné, en invoquant bien évidemment la loi de Murphy pour justifier de tomber en panne au pire moment.
Désolé de vous avoir fait attendre pour la suite de cette série sur le code PL/SQL et SonarQube, mais j’ai été pas mal occupé, entre voyages, travail et mon portable qui m’a lâchement abandonné, en invoquant bien évidemment la loi de Murphy pour justifier de tomber en panne au pire moment.
Rappel sur les posts précédents : après avoir configuré une analyse de code PL/SQL avec SonarQube, nous avons constitué notre propre Quality Profile en orientant les règles Blockers et Criticals sur la robustesse, la performance et la sécurité. A quoi ressemble maintenant notre tableau de bord ?
Nous avons d’abord examiné dans le post précédent les métriques de taille pour constater que le nombre moyen de lignes de codes par objet (procédure, fonction, trigger, etc.) était correct.
Grâce au nouveau widget File Bubble Chart nous avons découvert qu’un fichier unique ‘CreatePackageBody.sql’ de plus de 58 000 lignes, embarquait toute la logique métier au niveau de la base de données, ce qui va très certainement entraîner un coût de maintenance élevé pour cette application.
Complexité et duplications
Complexité
 Un coup d’œil sur la Complexité Cyclomatique (CC) aboutit à des résultats semblables : la complexité moyenne par objet est relativement basse avec 6.9 points de CC, et un maximum de 12 points. Par contre, la complexité par fichier dépasse les 600 points, et nous avons un total d’un peu plus de 10 000 points de CC dans toute l’application, ce qui est assez peu.
Un coup d’œil sur la Complexité Cyclomatique (CC) aboutit à des résultats semblables : la complexité moyenne par objet est relativement basse avec 6.9 points de CC, et un maximum de 12 points. Par contre, la complexité par fichier dépasse les 600 points, et nous avons un total d’un peu plus de 10 000 points de CC dans toute l’application, ce qui est assez peu.
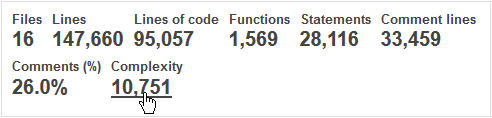
L’effort de tests pour celle-ci n’est donc pas très élevé. Rappelons que la Complexité Cyclomatique est une mesure du nombre de ‘chemins’ différents dans une application. Idéalement, tous ses chemins doivent être testés, donc la CC nous donne une idée de l’effort de tests.
On considère qu’à partir de 20 000 points pour une application, il est nécessaire d’effectuer une étape spécifique de QA et de rédiger des cahiers de test, et si possible d’automatiser ceux-ci avec un outil spécifique. Dans notre cas, nous pouvons laisser l’équipe de projet réaliser ces tests en interne.
Mais comme on peut le voir avec le Treemap ci-dessous, que j’ai configuré pour afficher la Complexité Cyclomatique …
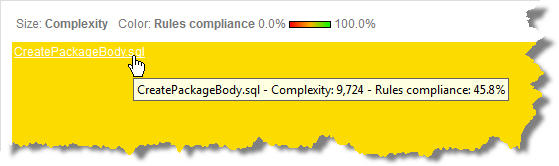
Notre fichier ‘CreatePackageBody.sql’ embarque 90% de la complexité et donc de la logique de l’application. Donc encore une fois, nous avons des chiffres qui sont corrects au niveau d’une application … sauf qu’ici l’application tient pratiquement dans un seul fichier monstrueux.
Duplications
 Après la complexité, je vais regarder le niveau de duplication, assez élevé. Pas de surprise, le même fichier monstre qui implémente la logique applicative est là encore en tête.
Après la complexité, je vais regarder le niveau de duplication, assez élevé. Pas de surprise, le même fichier monstre qui implémente la logique applicative est là encore en tête.

Cependant, nous rencontrons un nombre élevé de Copier/Coller dans les autres fichiers, et en particulier le fichier ‘Create_Tables.sql’. Puisque ce script se charge de créer les tables de la base de données, cela signifie que nous avons nombre de structures de données qui sont dupliquées.
Ce qui pourrait indiquer que le modèle de données n’est pas optimisé. Cela arrive pour une application ancienne, car il est plus facile d’ajouter de nouvelles tables que de faire évoluer celles existantes. Mais plus de tables signifie plus de jointures, donc une moindre performance et plus de complexité pour maintenir ces structures de données.
Dans le cadre d’un véritable audit de la qualité de cette application, je prendrais le temps de me plonger dans ce script de création de tables afin de vérifier cette hypothèse, et trouver quelques exemples qui puissent supporter une recommandation de refactoring de la base de données.
Par exemple, je compte 687 ‘CREATE TABLE’ dans ce fichier, donc 687 tables en tout (sans compter les vues). 8 963 lignes dupliquées dans ce script signifie en moyenne 13 lignes, donc 13 champs semblables par table. Il est logique d’avoir quelques champs ‘clés’ répétés pour pouvoir effectuer des jointures, mais peut-être pas à ce point là.
Composants à risque
Après avoir regardé les métriques quantitatives, nous avons déjà pas mal d’informations concernant cette application, certainement plus d’ailleurs que n’en connaissent habituellement les responsables de celle-ci, pour ne pas parler des stakeholders ou responsables informatiques.
La seconde partie d’une évaluation de la qualité consiste à identifier les principales menaces, et cela passe par le recensement des composants les plus risqués. Nous avons vu, dans les posts précédents :
- 16 blockers concernant la règle ‘Use IS NULL and IS NOT NULL instead of direct NULL comparisons’, et de surcroît ceux-ci dupliqués plusieurs fois : quelqu’un dans l’équipe nécessite probablement un rappel concernant cette règle.
- 2 ‘Calling COMMIT or ROLLBACK from within a trigger will lead to an ORA-04092 exception’. Et 1 ‘Do not declare a variable more than once in a given scope (PLS-00371)’ : probables erreurs d’inattention, la perfection n’est pas de ce monde. Dans tous les cas, à corriger d’urgence pour le risque encouru par les utilisateurs.
Après avoir remonté un certain nombre de règles Major en Critical, nous avons maintenant :
- 320 ‘Sensitive SYS owned functions should not be used’, dont 270 dans notre fichier ‘CreatePackageBody.sql’ : c’est l’inconvénient de faire du Copier/Coller, on duplique des défauts critiques pour la sécurité de l’application.
- Un certain nombre de défauts critiques, pour des règles Major que nous avons remonté dans cette catégorie Critical.

La plupart de ces règles impactent la performance ou la robustesse de l’application, donc présentent un risque pour l’utilisateur final.
Un chantier est donc recommandé pour corriger ces défauts dans l’application, surtout si la satisfaction des utilisateurs est un objectif important pour notre département IT. Mais quel en serait le coût ?
C’est ce que nous verrons dans le prochain post, avec le plugin Sqale pour la Technical Debt.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.