
 Nous continuons cette série sur les différents Use Cases qui peuvent se présenter dans le cadre de la reprise d’une application Lecagy en C, à partir de l’analyse du code source de Word 1.1a, la première version de ce traitement de texte publié par Microsoft en 1990.
Nous continuons cette série sur les différents Use Cases qui peuvent se présenter dans le cadre de la reprise d’une application Lecagy en C, à partir de l’analyse du code source de Word 1.1a, la première version de ce traitement de texte publié par Microsoft en 1990.
Les deux premiers posts ont été consacrés aux métriques quantitatives de taille (LOCs), de complexité (CC), le niveau de commentaires et de duplication, ainsi qu’aux différentes ‘Issues’ de type Blocker, Critical, Major et Minor.
Afin de pouvoir chiffrer au mieux différentes stratégies, notamment de refactoring et de réingénierie, nous avons commencé à travailler sur la Complexité Cyclomatique (CC) des fonctions et leur distribution. Nous allons maintenant effectuer ce même travail sur les fichiers, afin d’identifier lesquels sont les plus complexes et/ou incorporent des fonctions également complexes.
Complexité
Programmes
Le tableau suivant présente la répartition de la complexité parmi les fichiers :
Tableau 4 – Complexité Cyclomatique des fichiers de l’application Word Opus
 171 fichiers n’ont aucune Complexité Cyclomatique. J’ai recensé 130 fichiers .h dans l’application, dont la plupart porte sur la définition de structures de données ou de constantes, donc sans aucun algorithme correspondant à une règle fonctionnelle ou technique. D’autre part, 156 fichiers ont une CC supérieure à 90, donc cette application est extrêmement polarisée entre des fichiers avec une complexité faible ou même nulle, et des fichiers avec une complexité élevée. Ou très élevée, puisque là encore, une règle de type ‘Major’ me permet d’identifier 159 fichiers avec plus de 80 points de CC.
171 fichiers n’ont aucune Complexité Cyclomatique. J’ai recensé 130 fichiers .h dans l’application, dont la plupart porte sur la définition de structures de données ou de constantes, donc sans aucun algorithme correspondant à une règle fonctionnelle ou technique. D’autre part, 156 fichiers ont une CC supérieure à 90, donc cette application est extrêmement polarisée entre des fichiers avec une complexité faible ou même nulle, et des fichiers avec une complexité élevée. Ou très élevée, puisque là encore, une règle de type ‘Major’ me permet d’identifier 159 fichiers avec plus de 80 points de CC.
![]() Comme pour les fonctions, j’ai calculé la distribution des fichiers les plus complexes.
Comme pour les fonctions, j’ai calculé la distribution des fichiers les plus complexes.
Tableau 5 – Distribution des fichiers les plus complexes
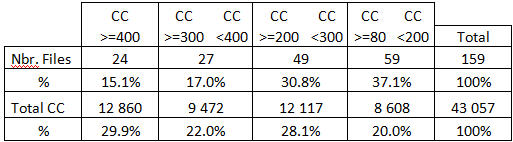 159 fichiers, soit 45,6% des 349 fichiers que compte l’application, ont plus de 80 points de CC, et totalisent entre eux 43 058 points de CC, soit 98,2% de la Complexité Cyclomatique globale (43 846). Quand je vous dis que cette application est polarisée en matière de complexité des programmes !
159 fichiers, soit 45,6% des 349 fichiers que compte l’application, ont plus de 80 points de CC, et totalisent entre eux 43 058 points de CC, soit 98,2% de la Complexité Cyclomatique globale (43 846). Quand je vous dis que cette application est polarisée en matière de complexité des programmes !
On notera 24 fichiers au-delà de 400 points de CC, donc là encore – tout comme pour les fonctions – un nombre limité d’objets (15%) constitue une part importante (30%) de la complexité globale. Avec les 27 fichiers à plus de 300 points de CC, cela nous fait 51 programmes (14.6% des 349 fichiers de l’application), au-delà de 300 CC et une complexité totale (12 860 + 9 472) égale à 22 332, soit 51% de l’ensemble de la Complexité Cyclomatique pour toute l’application (43 846).
J’ai également vérifié comment se répartissent les fonctions les plus complexes parmi ces programmes :
- 3 fichiers à plus de 400 CC comptent au moins 1 fonction à plus de 200 CC et 1 fonction à plus de 100 CC (en rouge ci-dessous).
- 1 fichier à plus de 400 CC et 2 fichiers à plus de 300 CC avec au moins 1 fonction à plus de 200 CC (en orange foncé).
- 7 fichiers à plus de 400 CC avec au moins 1 fonction à plus de 100 CC (en orange clair).
- 6 fichiers à plus de 300 CC avec au moins 1 fonction à plus de 100 CC (en jaune).
Figure 1 – Croisement des fonctions et fichiers les plus complexes
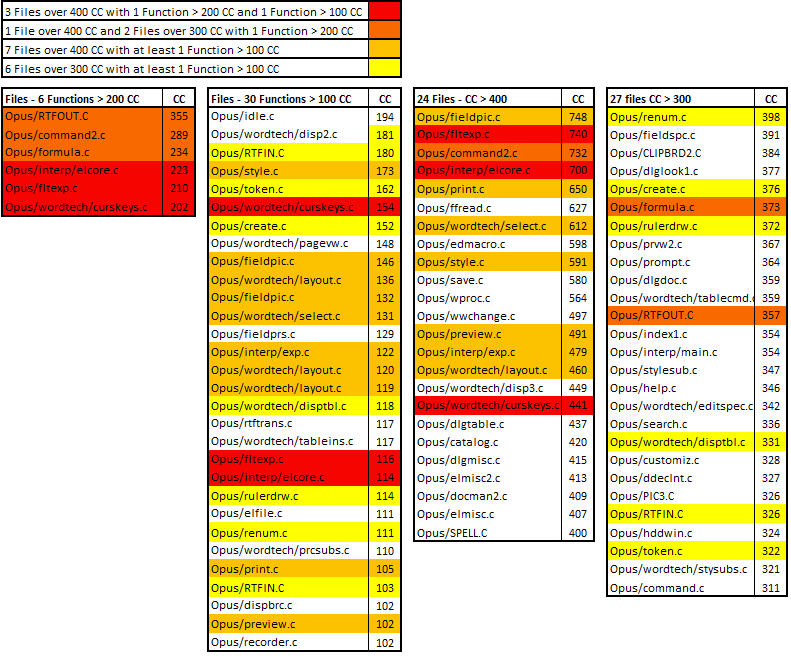 Nous savons donc maintenant quelles fonctions et quels fichiers traiter en priorité, sur lesquels portera d’abord notre effort, ainsi qu’une estimation de leur niveau de complexité.
Nous savons donc maintenant quelles fonctions et quels fichiers traiter en priorité, sur lesquels portera d’abord notre effort, ainsi qu’une estimation de leur niveau de complexité.
Taille
Comme nous l’avons vu dans le post précédent, la taille est également un des éléments d’appréciation des charges de refactoring ou de réingénierie.
Fonctions
Je dispose également d’une règle qui me permet d’identifier les fonctions qui dépassent un certain seuil de taille, au-delà de 100 lignes de code. ![]() J’ai à nouveau regardé la répartition des fonctions avec le plus grand nombre de lignes de code.
J’ai à nouveau regardé la répartition des fonctions avec le plus grand nombre de lignes de code.
Tableau 6 – Distribution des fonctions selon leur taille
Sur 478 fonctions à plus de 100 LOCs :
- 3 fonctions dépassent les 1 000 lignes de code.
- 21 comptent plus de 500 lignes de code.
- 126 sont entre 200 et 500 lignes de code.
J’ai également croisé la taille (LOCs) avec la Complexité Cyclomatique, pour les résultats suivants :
- La fonction la plus complexe, avec 355 points de CC compte 2 063 lignes de code (dans le fichier ‘Opus\RTFOUT.c’) !
- Sur les 6 fonctions les plus complexes, au-delà de 200 CC, 3 ont une taille supérieure à 1 000 LOCs (dont la précédente), 2 autres dépassent les 700 lignes et la dernière atteint 393 lignes.
- Sur les 30 fonctions recensées précédemment à plus de 100 CC, 15 ont une taille entre 500 et 1 000 LOCs, et les 15 autres entre 250 et 500 LOCs.
Sans aucune surprise, on retrouve ces fonctions dans les fichiers identifiés en rouge/orange dans la figure 1 précédente.
Programmes
Nous avons vu que la complexité était très polarisée entre les fichiers, avec 159 d’entre eux au-delà de 80 points de CC. Une autre règle nous permet également de constater 149 fichiers qui comptent plus de 1 000 lignes de code.
![]() Nous avons 9 fichiers au-delà de 3 000 lignes, dont 1 a 4 117 LOCs, et 36 fichiers entre 2 000 et 3 000 lignes. J’ai vérifié pour ces 9 fichiers les plus importants s’ils comptaient des fonctions également volumineuses, et dans quelles proportions (nombre et taille de ces fonctions).
Nous avons 9 fichiers au-delà de 3 000 lignes, dont 1 a 4 117 LOCs, et 36 fichiers entre 2 000 et 3 000 lignes. J’ai vérifié pour ces 9 fichiers les plus importants s’ils comptaient des fonctions également volumineuses, et dans quelles proportions (nombre et taille de ces fonctions).
Tableau 7 – Croisement des fichiers les plus volumineux avec les fonctions de taille élevée
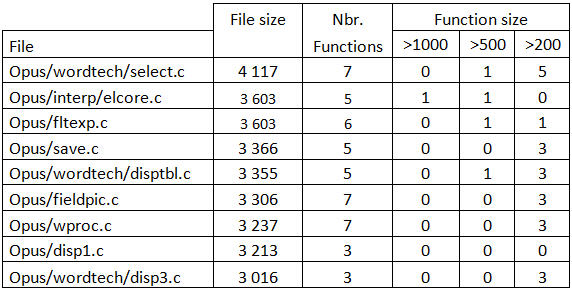 La colonne ‘Nbr. Functions’ liste le nombre de fonctions de plus de 100 LOCs dans le fichier, puis les 3 colonnes ‘Function size’ le nombre de fonctions au delà de 1 000 / 500 / 200 LOCs. Par exemple :
La colonne ‘Nbr. Functions’ liste le nombre de fonctions de plus de 100 LOCs dans le fichier, puis les 3 colonnes ‘Function size’ le nombre de fonctions au delà de 1 000 / 500 / 200 LOCs. Par exemple :
- Le fichier ‘Opus\wordtech\select.c’ comporte 7 fonctions de plus de 100 lignes, dont 1 de plus de 500 lignes et 5 de plus de 200 lignes.
- Le fichier ‘Opus\interp\elcore.c’ comporte 5 fonctions de plus de 100 lignes dont 1 de plus de 1 000 lignes et 1 de plus de 500 lignes.
- …
On constate que le nombre de fonctions de taille importante décroît proportionnellement à la taille du fichier. J’ai noté 2 exceptions cependant :
- Le fichier ‘RTFOUT.c’ avec 2 222 LOCs et la fonction la plus complexe : 355 points de CC et 2 063 lignes de code.
- Le fichier ‘formula.c’ avec 2 179 LOCs et une fonction à plus de 1 000 lignes de code.
Egalement, sur les 36 fichiers entre 2 000 et 3 000 LOCs :
- 8 fichiers entre 2 000 et 3 000 LOCs comptent 10 fonctions à plus de 500 LOCs, dont 6 avec de surcroît au moins 1 fonction à plus de 200 LOCs.
- 25 fichiers entre 2 000 et 3 000 LOCs comptent 25 functions entre 200 et 500 LOCs.

Nous avons identifié les fonctions et les fichiers qui péseront le plus sur la difficulté et donc les coûts de refactoring et de réingénierie, de par leur taille et leur complexité.
Dans le prochain post, nous vérifierons si ces fichiers comportent également des défauts de structure (bloc imbriqués, goto, etc.) qui rendront encore plus difficile la compréhension et l’évolution de son code.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.