
 Nous avons cette application Legacy en C, la première version de Word publiée par Microsoft en 1990, pour laquelle nous nous proposons de chiffrer le coût de différentes stratégies : refactoring ou reengineering, par la même équipe de développeurs ou au contraire, par une autre équipe et donc avec un transfert de connaissances.
Nous avons cette application Legacy en C, la première version de Word publiée par Microsoft en 1990, pour laquelle nous nous proposons de chiffrer le coût de différentes stratégies : refactoring ou reengineering, par la même équipe de développeurs ou au contraire, par une autre équipe et donc avec un transfert de connaissances.
Après avoir analysé le code source de cette application, nous avons pu identifier les composants (programmes et fonctions) les plus complexes (Complexité Cyclomatique) et/ou avec une taille importante.
Aujourd’hui, nous allons regarder si ces programmes comportent également des violations aux bonnes pratiques de programmation susceptibles de peser sur la lisibilité et la compréhension du code, avec l’impact que l’on imagine sur les coûts de nos différentes stratégies.
Switch case
Un ‘switch’ est, comme vous le savez probablement, une instruction qui permet de tester différents cas (‘cases’), ou conditions multiples. Evidemment, plus le traitement de chaque cas sera long et complexe, et plus l’ensemble de l’instruction sera longue – parfois sur plus d’une page – et difficile à comprendre.
La règle suivante identifie le nombre de ‘switch cases’ avec plus de 5 lignes.
![]() Je me suis intéressé à nouveau à la distribution des violations à cette bonne pratique selon la taille du ‘switch case’. En-dessous de 20 lignes, quelques minutes seront suffisantes pour comprendre, voire corriger ce défaut. Au-delà de 100 lignes, la compréhension de l’algorithme et des cas testés devient beaucoup plus difficiles.
Je me suis intéressé à nouveau à la distribution des violations à cette bonne pratique selon la taille du ‘switch case’. En-dessous de 20 lignes, quelques minutes seront suffisantes pour comprendre, voire corriger ce défaut. Au-delà de 100 lignes, la compréhension de l’algorithme et des cas testés devient beaucoup plus difficiles.
Tableau 8 – Distribution des ‘switch cases’ selon leur taille
 19 ‘switch cases’ comportent plus de 100 lignes. J’ai voulu croiser ceux-ci avec les fonctions les plus complexes. Vous vous rappelez que dans le premier post de cette série, nous avons identifié 30 fonctions à plus de 100 points de CC (Complexité Cyclomatique) et 6 à plus de 200 CC. Dans le second post, nous avions croisé ces 36 fonctions avec les programmes les plus complexes, avec un code couleur :
19 ‘switch cases’ comportent plus de 100 lignes. J’ai voulu croiser ceux-ci avec les fonctions les plus complexes. Vous vous rappelez que dans le premier post de cette série, nous avons identifié 30 fonctions à plus de 100 points de CC (Complexité Cyclomatique) et 6 à plus de 200 CC. Dans le second post, nous avions croisé ces 36 fonctions avec les programmes les plus complexes, avec un code couleur :
- Orange foncé pour des fonctions à plus de 200 CC dans des programmes à plus de 300 CC : deux de ces fichiers apparaissent dans le tableau ci-dessous : ‘RTFOUT.C’ et ‘formula.c’.
- Orange clair pour le programme ‘print.c’ à plus de 400 CC avec au moins une fonction à plus de 100 CC.
- Jaune pour le programme ‘RTFIN.c’ à plus de 300 CC avec au moins 1 fonction à plus de 100 CC.
- Blanc pour les programmes ‘wordtech\tableins.c’ et ‘rtftrans.c’ à plus de 200 CC avec au moins 1 fonction à plus de 100 CC.
Tableau 9 – Croisement des ‘switch cases’ les plus longs avec les fonctions les plus complexes
 Ce tableau montre que la majorité (10 sur 16) des ‘switch cases’ de taille importante se trouvent dans des fonctions identifiées comme très complexes. La colonne ‘Line Switch’ affiche la ligne de code où débute le ‘switch case’. Je connais également la ligne où débute la fonction (‘Line Fn’) ainsi que la taille de celle-ci en nombre de lignes (‘Fn Size’), ce qui me permet de calculer la ligne de code où se termine la fonction (‘End Fn’) et donc de vérifier si le ‘switch case’ se trouve bien au sein de celle-ci (‘In’).
Ce tableau montre que la majorité (10 sur 16) des ‘switch cases’ de taille importante se trouvent dans des fonctions identifiées comme très complexes. La colonne ‘Line Switch’ affiche la ligne de code où débute le ‘switch case’. Je connais également la ligne où débute la fonction (‘Line Fn’) ainsi que la taille de celle-ci en nombre de lignes (‘Fn Size’), ce qui me permet de calculer la ligne de code où se termine la fonction (‘End Fn’) et donc de vérifier si le ‘switch case’ se trouve bien au sein de celle-ci (‘In’).
Par exemple :
- Le fichier ‘RTFOUT.C’ est un programme de plus de 300 points de CC (orange foncé) avec une fonction de 355 CC, au sein de laquelle on trouve 2 ‘switch cases’, respectivement de 296 et 181 lignes de code.
- Le fichier ‘formula.c’ est également un programme de plus de 300 CC (orange foncé) avec une fonction de 234 CC et 3 ‘switch cases’ de 126, 105 et 183 lignes de code.
- Etc.
L’existence de structures de code longues et difficiles à comprendre, telles que le ‘switch case’ est un facteur aggravant des coûts de transfert de connaissances pour ces programmes et ces fonctions déjà très complexes.
Nombre de paramètres
Autre règle que j’ai souhaitée vérifier : les fonctions comportant un nombre élevé de paramètres.
![]() 43 fonctions comportent plus de 7 paramètres. Ce nombre n’est pas très élevé, si on compare avec la complexité de certaines fonctions ou leur taille en nombre de lignes.
43 fonctions comportent plus de 7 paramètres. Ce nombre n’est pas très élevé, si on compare avec la complexité de certaines fonctions ou leur taille en nombre de lignes.
Tableau 9 – Fonctions complexes avec un nombre élevé de paramètres
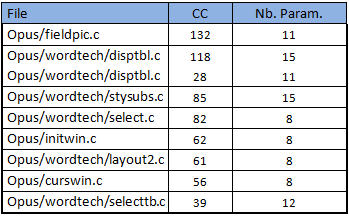 Le tableau précédent permet de constater que ces fonctions avec un nombre de paramètres élevées ne figurent pas parmi les plus complexes. Au moins, nous n’aurons pas de souci de ce côté là.
Le tableau précédent permet de constater que ces fonctions avec un nombre de paramètres élevées ne figurent pas parmi les plus complexes. Au moins, nous n’aurons pas de souci de ce côté là.
Goto
Comme nous le savons tous, un ‘goto’ est une instruction de ‘saut’ vers une autre portion de code, qui rompt la continuité du flux de traitement. Cette instruction est devenue le symbole même du code ‘spaghetti’, difficile à lire et à maintenir.
On en rencontre un nombre très élevé dans l’application.
![]() En fait, un coup d’œil dans le code montre que cette pratique est généralisée dans toute l’application. Par exemple, la gestion des erreurs se fera non pas par l’appel d’une fonction spécifique mais par un ‘goto’ vers la portion de code correspondante, parfois même dans une librairie externe.
En fait, un coup d’œil dans le code montre que cette pratique est généralisée dans toute l’application. Par exemple, la gestion des erreurs se fera non pas par l’appel d’une fonction spécifique mais par un ‘goto’ vers la portion de code correspondante, parfois même dans une librairie externe.
Le tableau suivant présente la répartition des ‘goto’ dans les programmes les plus complexes, comportant plus de 300 points de CC.
Tableau 11 – Distribution des Goto dans les programmes les plus complexes ( > 300 CC)

1 383 ‘goto’, soit 54% de leur nombre total (2 541) se rencontrent dans des programmes avec une Complexité Cyclomatique très élevée, voire extrêmement élevée.
Vous vous rappelez que dans le second épisode de cette série, nous avons listé les fichiers avec une complexité globale élevée et qui comportait au moins une fonction très complexe.
Tableau 9 – Fichiers complexes avec un nombre élevé de Goto
 On retrouve, avec donc un grand nombre de ‘goto’ :
On retrouve, avec donc un grand nombre de ‘goto’ :
- 2 fichiers à plus de 400 CC avec au moins 1 fonction à plus de 200 CC et 1 fonction à plus de 100 CC (en rouge ci-dessous), comptant également 87 et 32 ‘goto’.
- 7 fichiers à plus de 400 CC avec au moins 1 fonction à plus de 100 CC (en orange).
Nous avons au total :
- 142 ‘goto’ dans 2 programmes à plus de 700 CC.
- 86 ‘goto’ dans 3 programmes à plus de 600 CC.
- 200 ‘goto’ dans 4 programmes à plus de 500 CC.
- 350 ‘goto’ dans 11 programmes à plus de 400 CC.
Autres ‘bad practices’
J’ai continué ce travail de croisement entre les programmes les plus volumineux et les plus complexes avec les violations aux bonnes pratiques impactant la lisibilité et la compréhension du code, comme par exemple ‘’continue’ should not be used (MISRA C 14.5)’ ou ‘If statements should not be nested too deeply’.
Je ne vais pas lister tous ces résultats. Ces défauts se rencontrent en nombres (relativement) moins importants que ceux recensés ci-dessus, mais vont toucher également les programmes et fonctions les plus complexes.
Enfin, notre objectif n’est pas de réaliser une étude complètement exhaustive et extrêmement précise – il nous faudrait pour cela une dizaine ou plus de posts – sinon d’illustrer une démarche possible pour calculer les coûts de refactoring ou de réingénierie d’une application. Nous aborderons cette estimation dans le prochain post.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.