
 Nous avons présenté dans les deux posts précédents la notion de tests (unitaires) de caractérisation, proposée par Michael Feathers dans son livre ‘Working Effectively with Legacy Code’.
Nous avons présenté dans les deux posts précédents la notion de tests (unitaires) de caractérisation, proposée par Michael Feathers dans son livre ‘Working Effectively with Legacy Code’.
Nous avons montré brièvement comment nous pouvons utiliser de tels tests afin d’acquérir la connaissance du comportement de l’application. Je dis bien brièvement car, idéalement, il nous aurait fallu développer et présenter quelques tests à titre d’exemple, mais cela nécessiterait plusieurs posts, et cette série est déjà bien longue. Je vous renvoie au livre de Michael Feathers si vous souhaitez approfondir cette question.
Retenons simplement que l’écriture de ces tests facilitera le transfert de connaissances de notre application Legacy (Word 1.1a de Microsoft), et que toute opération ultérieure de refactoring ou de ré-engineering en sera plus rapide et plus sûre.
Couverture de tests
Mais quelle doit être l’ampleur de cette opération de ‘caractérisation’ ? Quand pouvons-nous considérer que notre couverture de tests est suffisante, et commencer à effectuer des modifications dans le code ? Est-il possible de chiffrer l’effort que cela représente ?
Michael Feathers recommande d’écrire autant de tests que nous pouvons juger nécessaire, pour chaque bloc de code que nous aurons à modifier dans le futur. Cependant, que se passe-t-il s’il n’est prévu aucune modification de code dans le futur ?
Ce n’est pas un cas si rare : lorsqu’une entreprise rachète un éditeur logiciel, elle peut souhaiter ne pas faire évoluer un produit, mais simplement en assurer le support jusqu’à ce qu’il meure de sa belle mort, lorsque plus aucun client ne paie la maintenance.
Autre cas : je connais des directions informatiques qui ont perdu presque complètement la connaissance de groupes entiers d’applications Cobol, PL1, Natural, Oracle Forms. Ces applications sont :
- Souvent critiques, car au cœur historique du système d’information.
- Complètement éprouvées, donc connaissent très peu de défauts et de maintenance corrective.
- Evoluent peu, et plutôt au niveau de leurs interfaces pour se brancher avec de nouvelles applications, qu’au niveau de leur logique métier.
Une stratégie possible pour ces directions informatiques consiste à outsourcer ce code, mais en veillant au transfert de connaissances, afin d’éviter de ‘casser’ ce qui marche bien.
La mission qui nous est assignée est de calculer le coût du transfert de connaissances de cette application vers une autre équipe. Comment pouvons-nous estimer cet effort de découverte du code à travers ces tests de caractérisation ? Existe-t-il une formule qui permette d’évaluer cet effort et planifier en conséquence les ressources nécessaires et un calendrier ?
Complexité et lisibilité
J’ai toujours considéré, dans les différents audits que je suis amené à réaliser, que la Complexité Cyclomatique était représentative de l’effort de tests.
Une petite application récente, non critique, interne à l’entreprise et sans utilisateurs extérieurs à celle-ci, avec environ 6 000 points de CC, peut se satisfaire de tests unitaires et d’intégration par l’équipe de projet, sans passer par une phase de QA formalisée.
Une application plus ancienne, ouverte sur l’extérieur – par exemple, un frontal ‘Clients’ de différentes autres applications et progiciels de commandes, facturation, stocks, etc. – donc critique pour l’entreprise, et supérieure à plus de 60 000 points de CC : phase de QA obligatoire, par une équipe de testeurs spécialisée, avec cahiers de tests et jeux d’essai formalisés, et si possible automatisés.
 A ce sujet, nous avons vu que notre application comptait 43 846 points de CC, répartis dans 3 936 fonctions et 349 fichiers.
A ce sujet, nous avons vu que notre application comptait 43 846 points de CC, répartis dans 3 936 fonctions et 349 fichiers.
La répartition de la Complexité Cyclomatique parmi ces fonctions est la suivante :
Tableau 1 – Complexité Cyclomatique des fonctions de l’application Word 1.1a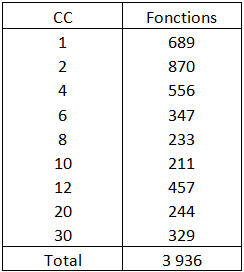
Je ne vais pas prendre comme objectif une couverture de tests de 100% de la Complexité Cyclomatique, car comme vous le savez probablement, au-delà d’une certaine limite, le temps d’écriture de nouveaux tests devient de plus en plus long. L’effort de test répond (approximativement) à une loi de Pareto selon laquelle il est possible d’écrire 80% des tests en 20% du temps.
En fait, je pense que 80/20 est un peu optimiste et je vais relativiser en considérant que 60% des tests sont réalisables en 50% du temps, et les 40% additionnels nécessiteront un autre 50%. Notre objectif principal est d’abord d’effectuer un transfert de connaissances vers une nouvelle équipe, pas d’atteindre une couverture de tests de 100%.
Par contre, les fonctions les plus complexes nécessitent une vigilance accrue, car elles présentent un risque plus important d’introduire un défaut à l’occasion d’une modification. Ces fonctions sont également candidates à un éventuel refactoring, donc une meilleure ‘caractérisation’, notamment si elles sont peu lisibles, avec un nombre élevé de lignes de code ou avec des défauts impactant la maintenabilité. Nous allons donc hausser notre exigence de tests pour celles-ci.
En conséquence, je vais poser les hypothèses suivantes :
- Pour les fonctions avec une CC inférieure ou égale à 20 points, la couverture de tests sera de 60% de la Complexité Cyclomatique.
- Pour les fonctions avec une CC supérieure à 20 points, nous souhaitons une couverture de 100% de la Complexité Cyclomatique.
SonarQube dispose d’une règle ‘Avoid too complex function’ qui liste les fonctions au-delà de 20 points de CC, avec leur nombre précis. Ceci nous a permis de calculer la distribution suivante :
Tableau 2 – Distribution des fonctions les plus complexes 
Une autre règle ‘Function/method should not have too many lines’, liste là encore les fonctions avec plus de 100 lignes de codes, et le nombre exact de ces dernières.
Je peux donc croiser ces deux listes afin d’identifier les fonctions avec plus de 20 points de CC et plus de 100 lignes de code. J’obtiens la distribution suivante :
Tableau 3 – Distribution des fonctions les plus complexes par taille (LOC)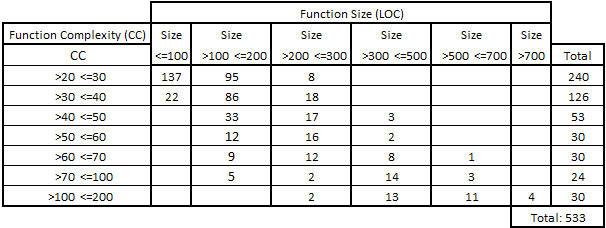
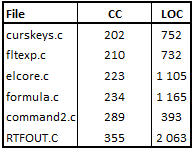
Je n’ai pas inclus dans le tableau précédent les 6 fonctions les plus complexes, au-delà de 200 points de CC, et qui se trouvent également dans des programmes complexes ou avec un grand nombre de lignes :
Tableau 4 – 6 programmes avec les fonctions les plus complexes
Estimation de l’effort de tests
Nous parvenons donc à une classification des différents composants en 3 catégories, des fonctions les plus simples avec peu de lignes, aux fonctions les plus complexes, de taille importante à très importante, et qui comptent également nombre de violations aux bonnes pratiques de programmation dommageables pour la compréhension du code.
Afin de calculer une mesure de l’effort de tests, je vais me baser sur la formule suivante :
Test Effort = Code Reading Time + Characterization Test
avec : Code Reading time = CC/2 (mn) x Readibility Factor%
et : Characterization Test = CC x N (mn)
J’utilise trois variables dans cette formule :
- Code Reading (CR) time sera le temps nécessaire pour ‘lire’ une fonction C et en déduire les tests de caractérisation correspondants.
- Readibility Factor% (RF%) sera un facteur de lisibilité du code.
- Characterization Test (CT) sera le temps d’écriture et d’exécution de ces tests, avec un nombre N de minutes dépendant de la Complexité Cyclomatique, et que je vais adapter en fonction du type de composant.
Rappelons nous qu’un test de caractérisation permet de décrire le comportement d’un bloc de code et donc, contrairement à un test unitaire ou à un test de régression, ne cherche pas à vérifier que ce code se comporte de manière correcte. Une compréhension complètement parfaite de la fonction et de chacune de ses variables, constantes, paramètres, valeurs d’input/output, … n’est donc pas requise. Raison pour laquelle je parle de ‘lire’ la fonction, c’est-à-dire déchiffrer celle-ci assez rapidement pour commencer à écrire des tests de caractérisation.
Cependant, plus une fonction sera peu complexe et peu lisible, avec des ‘goto’, des ‘switch’, etc. moins elle sera facile à appréhender. Je vais donc utiliser un facteur de lisibilité – Code Reading (CR) – afin de moduler ce temps de déchiffrage de la fonction.
Je vais également moduler le temps de réalisation des tests de caractérisation, car celui-ci sera différent selon le nombre de points de CC. Nous avons vu dans le dernier post que la fonction la plus complexe de notre application comportait des ‘switch’ avec des conditions sur plusieurs variables, assez rapidement compréhensibles et faciles à tester. Dans un tel cas, cela ne prendra pas beaucoup plus de temps pour tester un seul ‘switch’ avec 8 ou 10 points de CC qu’une fonction avec 2 ou 3 points de CC.
Je vais donc poser encore une fois les hypothèses suivantes :
- Pour les fonctions avec une CC inférieure ou égale à 20 points, le temps d’écriture des tests sera égal à 4 minutes par point de CC.
- Pour les fonctions avec une CC supérieure à 20 points, le temps d’écriture des tests sera égal à 2 minutes par point de CC.
Avec cette formule, une fonction avec une Complexité Cyclomatique égale à :
- 1, nécessite une demi-minute de temps de lecture et 4 mn de réalisation de test(s) de caractérisation, pour un total de 4 mn et 30 secondes.
- 2, nécessite 1 minute de temps de lecture et 8 mn de réalisation de tests pour un total de 9 minutes.
- 8, nécessite 4 minutes de temps de lecture et 32 mn de réalisation de tests pour un total de 36 minutes.
- 12, nécessite 6 minutes de temps de lecture et 49 mn de réalisation de tests pour un total de 54 minutes.
En fait, je n’ai pas la CC exacte pour les fonctions avec moins de 20 points, donc je vais considérer que le temps de réalisation des tests sera de 9 mn pour les fonctions des 2 à 4 points de CC, de 36 mn pour les fonctions de 8 à 10 points de CC, de 54 mn pour les fonctions de 12 à 20 points de CC, etc.
Ceci suppose un facteur multiplicateur de lisibilité du code (RF%) = 1. Je modifierai la valeur de ce facteur lorsque les fonctions vont devenir plus complexes (au-delà de 20 points de CC) ou moins lisibles.
Ces chiffres me semblent assez réalistes, ou en tout cas, ne me semblent pas sous-estimés. Je peux parfaitement présenter cette hypothèse de calcul à une équipe de projet ou des stakeholders : même s’ils comprendront qu’il s’agit d’une approximation, cette base me paraît acceptable afin de procéder à notre estimation.
Voyons un peu ce que cela nous donne, tout d’abord sur les fonctions à moins de 20 points de Complexité Cyclomatique :
Tableau 5 – Calcul de l’effort de test sur les fonctions les plus simples (< 20 CC)
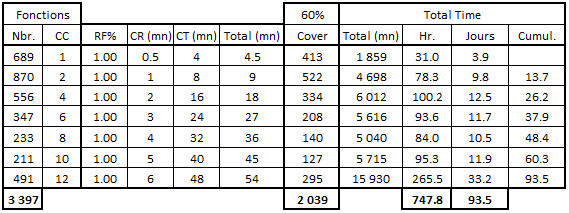 Nous comptons 3 397 fonctions de moins de 20 points de CC, pour lesquelles nous visons une couverture de 60% de tests de la Complexité Cyclomatique, et donc équivalent à 2 039 fonctions. Ainsi :
Nous comptons 3 397 fonctions de moins de 20 points de CC, pour lesquelles nous visons une couverture de 60% de tests de la Complexité Cyclomatique, et donc équivalent à 2 039 fonctions. Ainsi :
- 413 des 689 fonctions avec 1 point de CC, et un coût unitaire de test de 4.5 mn représentent 31 heures de travail soit prés de 4 jours (à 8 heures par jour).
- 522 des 870 fonctions avec 2 à 4 points de CC, et un coût unitaire de test de 9 mn représentent 78.3 heures de travail soit prés de 10 jours, pour un total cumulé (avec les 4 jours précédents) de prés de 14 jours.
- 295 des 491 fonctions avec 12 à 20 points de CC, et un coût unitaire de test de 54 mn représentent environ 33 jours de travail, soit un bon tiers des 93.5 jours nécessaires au total.
Gardons ce chiffre en tête pour l’instant et passons aux fonctions plus complexes. Nous avons dit que pour celles-ci :
- Nous souhaitons une couverture de tests égale à 100% de la Complexité Cyclomatique.
- Nous estimons le temps d’écriture d’un test de caractérisation au nombre de points de CC x 2 minutes.
Je vais également moduler le facteur de lisibilité (Readibility Factor ou RF%) de la manière suivante :
- Pour les fonctions inférieures à 100 lignes de code (LOC), RF% = 1.
- De 100 à 200 LOC, RF% = 1.5
- De 200 à 300 LOC, RF% = 2
- De 300 à 500 LOC, RF% = 2.5
- De 500 à 700 LOC, RF% = 4
- Au-delà de 700 LOC (mais moins de 200 points de CC), RF% = 10. Cela ne concerne que 4 fonctions, sans inclure les 6 fonctions les plus complexes, que nous verrons séparément.
Voici le tableau correspondant :
Tableau 6 – Calcul de l’effort de test sur les fonctions très complexes (20 < CC < 200)
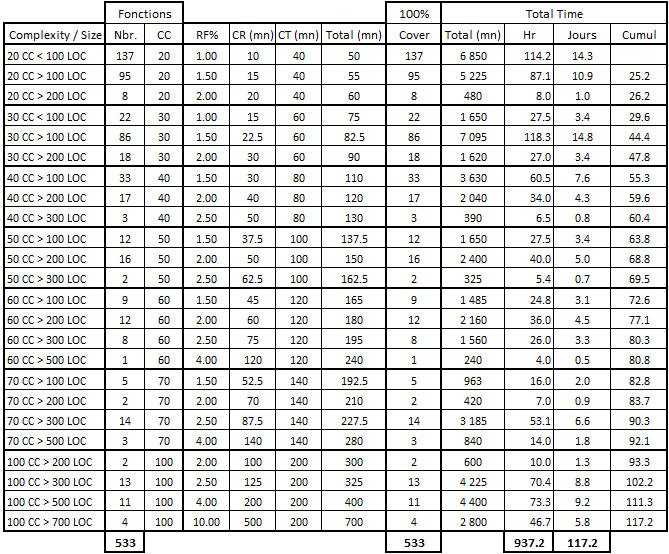
A titre d’explications, et afin de faciliter la compréhension de ce tableau :
- 137 fonctions avec une CC entre 20 et 30 points et moins de 100 LOC, représentant chacune une charge d’écriture de tests de 40 mn (RF% = 1) et une couverture de test de 100% de la CC, nécessitent 14.3 jours de travail.
- 95 fonctions avec une CC entre 20 et 30 points et une taille de 100 à 200 LOC, donc avec un Readibility Factor égal à 1.5 et une charge de tests de 55 mn par fonction, nécessitent 10.9 jours de travail. Le cumul avec la charge précédente est égal à 14.3 + 10.9 = 25.2 jours.
- 1 fonction avec une CC entre 60 et 70 points et une taille entre 500 et 700 LOC, avec un RF% de 4, aura un temps estimé de ‘lisibilité’ (Reading Time) de 120 mn (60 / 2 x 4) et un temps d’écriture de tests de 120 mn également, pour un total de 4 heures ou une demi-journée.
- 4 fonctions avec une CC entre 100 et 200 points et plus de 700 LOC, avec un RF% de 10, aura un temps estimé de 700 mn par fonction, pour un total de prés de 6 jours de travail afin de ‘caractériser’ ces 4 fonctions.
J’ai effectué un calcul spécifique à chacune des 6 fonctions les plus lourdes et complexes :
Tableau 7 – Calcul de l’effort de test sur les fonctions de complexité maximale (> 200 CC)
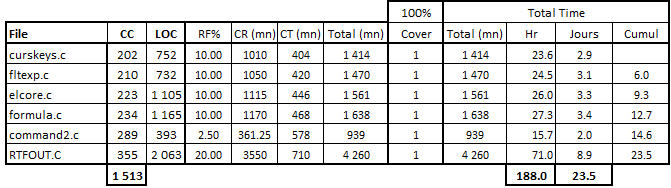
A part le programme ‘command2.c’ avec une fonction de moins de 400 lignes, et donc un facteur RF% de 2.5, j’ai affecté un RF% de 10 aux autres fonctions et un RF% de 20 pour la fonction la plus importante, dans le programme ‘RTFOUT.c’ (dont nous avons parlé dans le post précédent).
Synthèse
Sur la base des hypothèses que nous avons choisies, nous parvenons à un total de 234 jours pour la réalisation de tests de caractérisation sur notre application Legacy en C, avec un objectif de transfert de connaissances de cette application vers une autre équipe, ou à l’occasion d’un outsourcing.
Ces 234 jours, un peu moins de 12 mois/hommes (sur la base de 20 jours par mois) se répartissent de la facon suivante :
- 93.5 jours pour une couverture de tests de 60% de la Complexité Cyclomatique totale pour les 3 397 fonctions de moins de 20 points de CC.
- 117 jours pour une couverture totale des 533 fonctions entre 20 et 200 points de CC.
- 23.5 jours pour caractériser les 6 fonctions les plus complexes et les plus volumineuses.
Que penser de ces chiffres ? Nos hypothèses sont-elles correctes ou discutables ? Si nous devons présenter nos résultats devant l’équipe de projet ou le management, quelles sont les questions susceptibles d’apparaître et comment y répondre ? Quel plan d’action en tirer ?
Je vais vous laisser réfléchir à tout cela, en attendant d’aborder ces différents points dans notre prochain post.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.