
 Microsoft a publié cette semaine le code source de Word 1.1a (1990) via le Computer History Museum : http://www.computerhistory.org/atchm/microsoft-word-for-windows-1-1a-source-code/.
Microsoft a publié cette semaine le code source de Word 1.1a (1990) via le Computer History Museum : http://www.computerhistory.org/atchm/microsoft-word-for-windows-1-1a-source-code/.
Il s’agit d’une des premières versions de Word for Windows, de Janvier 1991 :
http://blogs.technet.com/b/microsoft_blog/archive/2014/03/25/microsoft-makes-source-code-for-ms-dos-and-word-for-windows-available-to-public.aspx.
Je me suis amusé à analyser le code source de cette version. J’étais curieux de voir quels seraient les résultats tant d’un point de vue quantitatif – nombre de lignes de code, niveau de complexité, etc – que qualitatif : violations aux bonnes pratiques de programmation, défauts de type Blockers, Criticals, etc.
Egalement, comment utiliser la dette technique dans un tel contexte ? Ce n’est pas tous les jours que l’on rencontre une application Legacy en C. Quels sont les Uses cases intéressants dans un tel contexte et en quoi l’analyse de la dette technique peut-elle nous aider ?
Mais nous reviendrons sur ce dernier point plus tard. Je ne sais pas encore combien de posts je vais consacrer à ces différents sujets. Dans ce premier article, je vais présenter succinctement la configuration d’analyse et les premiers résultats quantitatifs.
Analyse
Je ne vais pas rentrer dans trop de détails, car ce code source n’est pas publié sous licence libre et il est interdit de l’utiliser à des fins commerciales. Vous comprendrez bien que je n’ai pas du tout envie que Microsoft vienne me créer des ennuis si je mets en avant une entreprise ou un des ses produits. Je me contenterais donc de dire que j’ai effectué mes analyses avec SonarQube en version 4.2 et son plugin C/C++ en version 2.1.
 Si vous téléchargez le .zip correspondant au code de Word 1.1a, vous rencontrerez 3 répertoires correspondant à diverses versions, avec plus ou moins de documentation et d’utilitaires. J’ai utilisé la version la plus simple, ‘Opus’, qui se centre sur le code source.
Si vous téléchargez le .zip correspondant au code de Word 1.1a, vous rencontrerez 3 répertoires correspondant à diverses versions, avec plus ou moins de documentation et d’utilitaires. J’ai utilisé la version la plus simple, ‘Opus’, qui se centre sur le code source.
Il y a plusieurs types de fichiers qui ne peuvent être analysés : utilitaires .exe ou code assembleur par exemple. Je n’ai travaillé que sur des fichiers .c et .h. Les répertoires ‘lib’ et ‘resource’ ne contiennent que des .h. Les autres dossiers, y compris le répertoire principal ‘Opus’, contiennent des fichiers .c et .h.
Je n’ai pas cherché à déclarer les macros. Cela nécessite une connaissance précise de l’application, et sans travailler avec un architecte ou un membre de l’équipe de projet, cela peut prendre beaucoup de temps avant de comprendre comment tout le code est structuré. Ce serait indispensable pour rechercher des bugs potentiels, mais je ne vise pas une telle précision dans les résultats sinon plutôt une évaluation générale de la qualité.
J’ai rencontré quelques erreurs de parsing, essentiellement causées par des déclarations de types, pour une compilation sur Mac je pense. J’ai tenté divers types de syntaxe C (C89, C99 ou C11), sans que cela change quoique ce soit à ce niveau. Il s’agit essentiellement de structures de données que j’ai mises en commentaires, sans aucune incidence sur les résultats d’analyse, sinon qu’il me manquera quelques lignes de code dans le calcul final.
Il y a aussi des fichiers à ne pas analyser, comme par exemple un fichier qui commence par ‘THIS FILE IS OBSOLETE’ sans même que cette ligne soit en commentaire, donc il est normal que cela génère une erreur pour le parser.
Enfin, je me suis basé sur le Quality Profile par défaut de SonarQube, sans utiliser de règles supplémentaires comme par exemple celles de Cppcheck. Encore une fois, notre objectif n’est pas de débugguer Word, mais d’effectuer une analyse globale de la qualité du code, regarder la dette technique pour ce software et tenter d’en tirer quelques enseignements. Le tout dans le contexte de l’époque.
Métriques quantitatives
Ce que j’appelle les métriques quantitatives sont tous les résultats qui nous donnent une indication sur la taille et la complexité du code, le taux de commentaires, etc. Bref, tout ce qui ne concerne pas des bonnes pratiques de programmation.
Taille
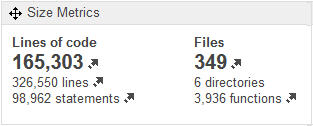 On trouve 326 500 lignes dans 349 fichiers, dont 165 milliers de lignes de code (KLocs). Je m’attendais à trouver beaucoup plus de lignes de code, mais ce qui est frappant selon moi est le petit nombre de fichiers. En moyenne, chaque fichier compte prés de 1 000 lignes, dont la moitié sont des lignes de code. Cela ne doit pas favoriser la lecture et la compréhension de celui-ci, surtout lorsqu’il s’agit d’un langage aussi complexe que le langage C.
On trouve 326 500 lignes dans 349 fichiers, dont 165 milliers de lignes de code (KLocs). Je m’attendais à trouver beaucoup plus de lignes de code, mais ce qui est frappant selon moi est le petit nombre de fichiers. En moyenne, chaque fichier compte prés de 1 000 lignes, dont la moitié sont des lignes de code. Cela ne doit pas favoriser la lecture et la compréhension de celui-ci, surtout lorsqu’il s’agit d’un langage aussi complexe que le langage C.
D’ailleurs, si l’on regarde la distribution du code en fichiers, à l’aide du Project File Bubble Chart, on peut remarquer quelques jolis monstres, comme ce fichier ‘fltexp.c’ qui compte 2 600 lignes de code et 506 issues. A noter que sa dette technique reste cependant limitée avec seulement 23 jours de refactoring estimée pour corriger les défauts identifiés.

Documentation
Le niveau de commentaires est correct sans être exceptionnel, je dirais même dans la fourchette basse de ce qu’on peut attendre généralement d’une application de nos jours, mais là encore, nous ne sommes pas en présence d’une application de gestion, mais d’un software.

De plus, le niveau de commentaires est important lorsque vous savez qu’une application peut être outsourcée, et que d’autres que ses auteurs vont devoir comprendre ce que fait le code, ce qui n’est pas le cas pour du code maintenu par une équipe de R&D. Enfin, 20% de niveau de commentaires était probablement correct il y a 30 ans, même si cela paraît plutôt bas aujourd’hui.
Duplications
J’ai été frappé par le niveau minimal de duplications. Et en allant vérifier dans le code, il s’agit essentiellement de structures de données.
Rappelons que nous ne sommes pas ici en présence d’un langage orienté objet, donc il n’est pas possible de créer des classes spécifiques à un ‘objet’ fonctionnel. Même ainsi, le niveau de duplication extrêmement bas montre une réutilisation optimale du code existant. Probablement indispensable pour une R&D qui doit développer et maintenir des logiciels, mais certainement pas aussi fréquent de nos jours.
Complexité
 Le niveau global de Complexité Cyclomatique est assez élevé, avec 43 846 points de complexité. Rappelons qu’à partir de 20 000 points, une application nécessite une phase de QA spécifique, avec des cahiers et des jeux de tests formalisés. A partir de 60 000, un outil d’automatisation des tests est fortement recommandé. De tels outils n’existaient pas au début des années 1990, donc je serais curieux d’en savoir un peu plus sur les pratiques de Microsoft à l’époque.
Le niveau global de Complexité Cyclomatique est assez élevé, avec 43 846 points de complexité. Rappelons qu’à partir de 20 000 points, une application nécessite une phase de QA spécifique, avec des cahiers et des jeux de tests formalisés. A partir de 60 000, un outil d’automatisation des tests est fortement recommandé. De tels outils n’existaient pas au début des années 1990, donc je serais curieux d’en savoir un peu plus sur les pratiques de Microsoft à l’époque.
La grande majorités des fonctions ne sont pas très complexes, mais plusieurs centaines sont toutefois supérieures à 12 points de CC, et un très grand nombre sont au-delà des 30 points de CC, ce qui en fait des objets complexes ou très complexes, avec un coût de maintenabilité élevé et un risque important d’introduire un défaut en cas de modification. La phase de QA se doit donc d’être encore plus exigeante.
Heureusement, nous avons vu que la réutilisabilité semblait assez bonne. On peut donc concentrer les tests de non régression sur les objets les plus complexes qui ont été modifiés.
 Ce haut niveau de complexité se confirme qu niveau des fichiers avec environ la moitié d’entre eux au-delà des 90 points de CC.
Ce haut niveau de complexité se confirme qu niveau des fichiers avec environ la moitié d’entre eux au-delà des 90 points de CC.
J’ai configuré ci-dessous le Bubble Chart pour croiser le nombre de lignes de code avec la complexité.

Une fois de plus, nous retrouvons le fichier ‘fltexp.c’ avec 2 600 lignes de code et un niveau de CC de 740. Quand je vous dis que c’est un monstre !
Evaluation
Que pouvons-nous dire à ce stade de notre évaluation ?
Le niveau très faible de code dupliqué m’incite à penser que les choix d’architecture ont porté principalement sur une réutilisation maximale des fonctions, et ainsi pouvoir dédier chaque fichier à une fonctionnalité spécifique, avec tous les objets nécessaires pour gérer celle-ci. Ce qui explique que certains fichiers sont très imposants, en taille comme en complexité.
Il faut rappeler que la mémoire était limitée à l’époque, et que la taille prise par un logiciel en mémoire constituait un critère décisif de la performance et donc du succès ou de l’échec de celui-ci. Donc priorité à l’efficacité en la matière, ce qui suppose d’éviter de dupliquer une même structure de données dans des fichiers différents, même si cela signifie des fichiers plus longs, plus lourds, plus complexes.
Ceci va probablement affecter la lisibilité, la compréhension et la maintainabilité du code.
Nous allons donc prêter attention à ces facteurs pour la suite de notre évaluation, dans notre prochain post sur les métriques qualitatives et le respect des bonnes pratiques de programmation.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.