
 Nous avons examiné dans le post précédent, les premiers résultats de l’analyse du code source de Word 1.1a (1990).
Nous avons examiné dans le post précédent, les premiers résultats de l’analyse du code source de Word 1.1a (1990).
Nous avons compté 349 fichiers, ce qui n’est pas énorme, mais avec une taille assez élevée : en moyenne plus de 470 LOC (Lines Of Code), et nombre d’entre eux bien au-delà des 1 000 LOC. Les métriques de complexité sont élevées également, et le taux de commentaires assez bas, mais c’était probablement normal à l’époque, il y a plus de 40 ans.
Le très faible niveau de duplication amène à penser que tous les composants nécessaires à l’implémentation d’une même fonctionnalité se retrouvent dans un même fichier, ce qui explique donc la taille et la complexité de nombre d’entre eux. Il semble que le mot d’ordre ait été : priorité à l’efficacité, au second plan la lisibilité et la compréhension du code.
Qu’en est-il maintenant du respect des bonnes pratiques de programmation ? C’est ce que nous allons regarder dans ce second article.
Respect des bonnes pratiques de programmation
Un coup d’œil au ‘Treemap of Components’ nous montre un niveau assez bas de respect des bonnes pratiques de programmation.

Les fichiers les plus nombreux et les plus complexes se trouvent dans le répertoire principal, et présentent entre 20% et 50% de ‘Rules compliance’ dans la plupart des cas.

Au total, plus de 40 000 ‘Issues’, la plupart de type ‘Major’ et une dette technique de plus de 1 200 jours.

Regardons maintenant quelles sont les règles enfreintes, par niveau de criticité. Pour rappel, j’ai utilisé le Quality Profile par défaut, « out of the box » comme disent les anglais, c’est-à-dire prêtes à l’emploi.
Blockers
Aucune violation aux règles de type Blocker, c’est ce que nous souhaitons voir dans toute application. Mais quelles sont exactement ces règles si bien respectées ?

La première constitue une bonne pratique en matière de gestion des exceptions, en C++. Donc pas de surprise si elle est parfaitement respectée ici : il n’y a pas une seule instruction ‘throw’ dans toute l’application.
La seconde concerne l’utilisation de trigraphs, dont je ne suis pas certain qu’ils existaient à l’époque. Je ne suis pas un spécialiste du langage C, mais il me semble que les trigraphs ont été introduits par la norme C89, donc bien après 1980. Quoiqu’il en soit, au moins nous savons que nous ne rencontrerons pas de défaut de ce type.
Criticals
Nous rencontrons 753 défauts de type Critical, la plupart d’entre eux concentrés sur 2 règles.
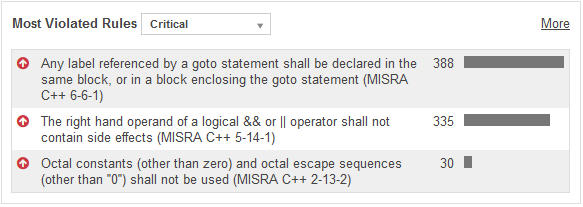
La première concerne l’utilisation de ‘goto’ afin d’effectuer un ‘jump’, c’est-à-dire d’aller directement à un endroit donné du code. Le ‘goto’ est devenu le symbole même du code ‘spaghetti’ dont la logique algorithmique est difficilement compréhensible, de par le nombre excessif de renvois dans tous les sens. Il n’est pas toujours possible de s’affranchir des ‘gotos’, mais il est souhaitable de disposer ceux-ci dans un même bloc de code, pour plus de lisibilité, et donc une meilleure fiabilité également.
Ce sont surtout les sauts vers des portions de code imbriqués qui sont dangereux. Un goto vers un bloc de plus haut niveau reste plus lisible, sauf lorsque votre programme fait plus de 1 000 lignes et que le saut vous envoie quelques pages plus bas dans celui-ci. Difficile de comprendre ce que fait le code lorsque vous passez votre temps à faire des allers-retours sur plusieurs pages. Il devient alors extrêmement difficile d’effectuer une modification sans introduire un bug. Les charges de maintenance et de tests en sont accrues.
La deuxième règle signale l’utilisation d’opérateurs logiques qui présente un risque d’effet de bord parce qu’elle aboutit à modifier une valeur autre que celle du code-retour, par exemple une variable globale, avec d’imprévisibles conséquences dans l’exécution du programme.
A noter que les 335 occurrences rencontrées dans le code ne sont pas forcément toutes des défauts, mais des violations potentielles.

Par exemple, dans le cas ci-dessus, si nous sommes sûrs que la fonction ‘DocOpenStDof’ ne modifie aucune valeur mais effectue une action comme par exemple, ouvrir un document Word, alors nous pourrions signaler qu’il ne s’agit pas en l’espèce d’un défaut, et de ne plus prendre en compte cette occurrence dans les futures analyses.
La troisième règle concerne l’utilisation de constantes en octal, qui présente un risque de confusion avec des valeurs entières. On n’en compte pas énormément ici, et si l’on considère que certaines portions de code de MS-DOS ont été réutilisées pour écrire cette version de Word, leur présence n’est pas très surprenante.
Major
Les violations aux règles ‘Major’ sont les plus nombreuses, de très loin. Je ne vais pas toutes les détailler, mais simplement commenter brièvement les plus notables.

La règle la plus enfreinte (plus de 9 000 violations) concerne l’utilisation d’accolades dans les traitements de type If-Else. En fait, l’examen du code montre que celles-ci ne sont pas employées lorsque le If ou le Else ne compte que très peu de lignes, comme par exemple un simple ‘return’ ou ‘goto’. Donc cette absence d’accolades n’est pas réellement significative d’un manque de lisibilité du code, puis que l’esprit de la règle est globalement respecté. Le problème est que cela crée des exceptions dangereuses, que l’on peut d’ailleurs constater dans le code : à partir de combien de lignes sans accolades le programme devient-il moins compréhensible ?
Je sortirais très probablement du Quality Profile la deuxième règle concernant les règles de nommage, comme c’est fréquemment le cas en matière de ‘naming conventions’ : que celles-ci ne soient pas respectées ne signifie pas qu’elles n’existent pas. Et puis, j’ai tendance à ranger celles-ci dans la catégorie ‘Minor’.
Les syntaxes de types K&R (Kernighan & Richie) sont obsolètes de nos jours, car considérées peu lisibles, mais ne l’étaient au début des 80’s.
La plupart des autres violations de type Major vont impacter également la lisibilité et la compréhension du code, comme on peut le voir ci-dessous.

J’ai configuré ce widget afin d’afficher les règles Major par nombre de défauts. La grande majorité sont des bonnes pratiques de programmation selon lesquelles éviter des traitements trop longs, comme ‘Switch cases should not have too many lines’ ou ‘Function/methods should not have too many lines’, des fonctions trop complexes (‘Avoid too complex function’ pour les fonctions comptant plus de 20 points de Cyclomatic Complexity), des règles de nommage (‘Literal suffixes shall be upper case’), etc.
Il y a en fait très peu de défaut Major qui soient susceptibles d’impacter la fiabilité et la robustesse de l’application, toutes proportions gardées bien évidemment.
Minor
Il en va d’ailleurs de même pour les règles de type Minor, celles-ci étant toutefois en nombre moins importants.

L’analyse des ‘Issues’ rencontrées dans le code de cette première version de World confirme nos impressions initiales : tout semble indiquer que les priorités ont portées sur l’efficacité et la fiabilité, puisque les violations de ce type sont les moins nombreuses. Par contre, les infractions aux bonnes pratiques en matière de maintenabilité et d’évolutivité du code constituent la grande majorité des ‘Issues’ constatées, ce qui explique la Technical Debt très importante pour une première version d’application.
Il y a certes quelques règles, comme celles de ‘Naming Conventions’ par exemple, que l’on pourrait désactiver. Je n’ai pas voulu modifier le Quality Profile par défaut pour effectuer l’analyse de ce code, mais il aurait sûrement fallu l’adapter aux caractéristiques d’une application C ‘Legacy’ telle que celle-ci.
Néanmoins, nous verrons dans le prochain post qu’il peut exister certains cas dans lesquels il vaut mieux démarrer notre évaluation en procédant de cette manière.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.