
 Continuamos esta serie sobre el análisis del código fuente de Word 1.1a, publicado por Microsoft en 1990.
Continuamos esta serie sobre el análisis del código fuente de Word 1.1a, publicado por Microsoft en 1990.
En el primer post, hemos visto las métricas cuantitativas de tamaño, de complejidad, el nivel de comentario y de duplicación. El segundo post fue dedicado a los diferentes ‘Issues’ Blocker, Critical, Major et Minor.
Estos resultados de análisis sugieren una estrategia de desarrollo orientada claramente hacia la fiabilidad y el rendimiento del software, ya que nos encontramos con pocas violaciones de mejores prácticas en este campo. Hay muchas más en términos de legibilidad y de comprensión del código, y por lo tanto de mantenimiento.
Recuerdo: hice este análisis de forma sencilla, es decir ‘out of the box’, sin nada de parametrización. He resuelto algunos problemas de parsing, pero no he intentado declarar macros, y he trabajado con el Quality Profile (conjunto de reglas) por defecto. Lo importante para mí, en esta serie, no es la búsqueda de la máxima precisión en los resultados, ya que el objetivo no es auditar el código de esta versión de Word, pero ver cómo una sencilla evaluación y algunos indicadores pueden ser útiles para tomar decisiones, dependiendo del contexto.
Casos de uso
¿Quién dice contexto dice casos de uso. Cuando hablamos de aplicaciones Legacy, los casos de uso más frecuentes serán:
- Externalización: transferir el mantenimiento de la aplicación a un nuevo equipo, usualmente una empresa de servicios, y con el fin de reducir los costes de mantenimiento.
- Refactorización: la deuda técnica creció hasta tal punto que cualquier modificación de código tiene un muy alto coste de cambio. Una refactorización es necesaria para reducir los intereses de la deuda.
- Reingeniería: una refactorización significa a menudo concebir de nuevo el diseño y la arquitectura de la aplicación. ¿Por qué no aprovechar esta oportunidad para re-escribir esta aplicación en otra tecnología, más reciente y más fácil de mantener?
- Abandono: abandonar esta aplicación? Esta es una pregunta que surge con frecuencia para aplicaciones Legacy, especialmente en el mundo Cobol. Si es más barato reemplazarla con un software de empresa (Enterprise Software), entonces podemos descartala.
Ahora voy a ponerme en un contexto muy concreto: has decidido comprar Microsoft. Sí, lo sé, es un poco difícil de imaginar, pero intentalo. Tu misión, si la aceptas, será recomendar una estrategia para esta versión de Word:
- Externalización: ¿cuál es el coste de transferir el conocimiento de esta aplicación a otro equipo de I + D?
- Refactorización: ¿cuál es el coste de resolver los defectos existentes encontrados (re-diseño incluido), con el equipo actual? O con un nuevo equipo después de una transferencia de conocimiento (caso 1 + 2)?
- Reingeniería: re-escribir esta aplicación en una nueva tecnología, como C++ (lo más logico). Con el mismo equipo o con otro equipo (caso 1 + 3).
- Abandono: decisión para el management, porque hay una dimensión estrategica. Si mantener el software cuesta más que lo que se puede ganar, se le permitirá morir de muerte natural, con una equipo reducido para resolver los defectos más críticos pero sin trabajar en la evolución de la aplicación.
Para evaluar los costes de estas diferentes estrategias, pensé en cuales de los diversos datos e informaciones disponibles en mi dashboard pueden ser utiles, y que tomar en cuenta para cada caso. Empezando con el e coste estimado de la transferencia de conocimientos de esta aplicación a un nuevo equipo. ¿Qué hace que un programa o una función será más o menos difícil de entender?
- Su tamaño: más largo un programa, más tiempo se requiere para conocer la lógica implantada y lo que hace.
- Su complejidad: cuanto más condiciones tiene un programa – que sean If … Else o Switch – y bucles, más difícil entender el flujo de tratamientos.
- Su estructura: cuanto más bloques de código imbricados, Goto, Break y otras instrucciones que inducen una lectura no lineal del código, más complicados los algoritmos.
Empecé con los datos de complejidad.
Complejidad
Funciones
Hemos visto en el primero post que esta aplicación tiene algunas funciones y archivos con un alto número de puntos de Complejidad Ciclomática (CC). De hecho, la distribución es la siguiente:
Tabla 1 – Complejidad Ciclomática de las funciones de la aplicación Word Opus 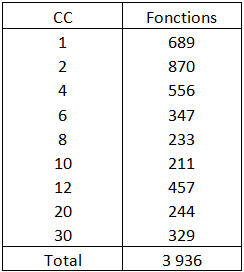
Podemos ver en esta tabla 689 funciones con una Complejidad Ciclomática igual a 1, luego 870 funciones de CC igual a 2 y menos de 4, etc.
Se considera que la distribución óptima de la Complejidad Ciclomática de una aplicación C es como sigue:
- Funciones pocas complejas con una CC < 4 (Low): 52% del número total de funciones en la aplicación.
- Funciones moderadamente complejas con una CC > 4 y < 10 (Moderate): 25%.
- Funciones complejas con una CC > 10 y < 20 (High): 15%.
- Funciones muy complejas con una CC > 20 (Very High): 8%.
Si se calcula la distribución de la complejidad en nuestra aplicación Word desde la Tabla 1, se obtiene esta siguiente:
Tabla 2 – Distribución de la complejidad en la aplicación Word Opus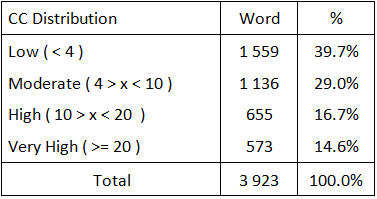
La siguiente figura muestra la curva de distribución de la complejidad en Word, en comparación con la curva ideal.
Figura 1 – Curva de distribución de la complejidad (Funciones) 
Vemos que la proporción de funciones de complejidad media o alta es en fase con la curva optimal:
- 29% de ‘Moderate’ en Word vs. 25% idealmente.
- 16.7% de ‘High’ en Word vs. 15% idealmente.
Pero, las funciones menos complejas no son suficientes: 39,7% en lugar de 52%. Y el nivel de funciones muy complejas es demasiado alto: 14,6% frente al 8% en el ideal. Esto debería afectar los costes de transferencia de conocimiento o la reingeniería de esta aplicación.
Entonces me he centrado en las funciones más complejas utilizando la siguiente métrica que lista las funciones con una Ciclomática Complejidad por encima de 20 puntos:![]() Hay que tener en cuenta que habíamos identificado en el primero post 573 funciones con una CC superior o igual a 20, lo cual significa que tenemos 34 funciones (573 – 539) con exactamente 20 puntos.
Hay que tener en cuenta que habíamos identificado en el primero post 573 funciones con una CC superior o igual a 20, lo cual significa que tenemos 34 funciones (573 – 539) con exactamente 20 puntos.
Estas funciones representan una complejidad ciclomática de 24 667, más de la mitad de la CC global (43 846, como se ve en en el primero post de esta serie) y algunas funciones son muy complejas:
Tabla 3 – Distributción de las funciones más complejas

Contamos con:
- 6 funciones más allá de 200 puntos de CC (la más grande, incluso llega a 355 puntos), para un total de 1 513 puntos de CC. Así que el 1% de las 539 funciones más complejas representan el 6% de la CC de todas estas funciones (1 513 / 24 667).
- 30 funciones entre 100 y 200 puntos de CC para un total de 3 921 puntos, o sea 5.6% de las 539 funciones más complejas y 15.9 % de la CC total de ellas.
Así que en resumen, 36 funciones representan el 22% de la complejidad global de estas 539 funciones.
En toda la aplicación, 36, es decir, el 0.9% de las 3 936 funciones existentes representan el 12.4% del total de la Complejidad Ciclomática (43 846 puntos).
Entonces, no falta decir que vamos a prestar especial atención a estos objetos, para evaluar el coste de nuestras tres opciones: transferencia de conocimiento, refactorización o reingeniería.
Vamos a seguir este artículo en el próximo post mediante el mismo trabajo de medición de complejidad, a nivel de los archivos.
Esta entrada está disponible también en Lire cet article en français y Read that post in english.