
 Hemos definido nuestro proyecto de reingeniería como la reescritura de nuestra aplicación Legacy con un nuevo lenguaje o su migración a una nueva tecnología, a diferencia de una refactorización que implica la reorganización del código y la corrección de ciertos defectos con el fin de hacerlo más mantenible y reducir la deuda técnica.
Hemos definido nuestro proyecto de reingeniería como la reescritura de nuestra aplicación Legacy con un nuevo lenguaje o su migración a una nueva tecnología, a diferencia de una refactorización que implica la reorganización del código y la corrección de ciertos defectos con el fin de hacerlo más mantenible y reducir la deuda técnica.
También vimos, con SonarQube y el plugin SQALE diferentes planes de refactorización más o menos ambiciosos, desde la resolución de los defectos más críticos hasta reducir la deuda técnica para llevarla a un nivel (rating SQALE) ‘A’.
Sin embargo, ¿qué es lo más interesante y productivo entre un proyecto de reingeniería y una refactorización?
Normalmente, la inversión será mayor para una reingeniería, ya que rara vez es posible modular el proyecto excepto en el caso de una reingeniería parcial, de la interfaz gráfica por ejemplo, cuando una refactorización se puede realizar a lo largo del tiempo.
Pero podemos suponer que los beneficios de la reingeniería serán mucho más altos que los de una refactorización puesto que la deuda técnica, si no desaparece por completo – siempre habrá objetos complejos o errores por falta de atención – pero al menos se reduce muy fuertemente. Esto si el proyecto de reingeniería es un éxito.
Porque los riesgos de fracaso son importantes:
- No se conoce bien la nueva plataforma, la nueva tecnología o el nuevo lenguage, o falta experiencia en esta área. La nueva aplicación tiene problemas de tiempo de respuesta.
- Se calculó mal el esfuerzo de reingeniería, se desarrolla rápidamente y se olvida las pruebas unitarias para cumplir con los plazos del proyecto. La nueva aplicación está repleta de bugs.
- Algunos de los procedimientos o procesos de negocio se han cambiado, con el pretexto de simplificarlos, pero de hecho, era para disminuir la carga del proyecto. La nueva aplicación no cumple con los requerimientos de negocio y es más compleja de usar.
- No se ha identificado con precisión los objetivos, los usuarios no están incluidos en el proyecto. Se enfrentará a muchas peticiones de cambio y se estalla el presupuesto.
Rendimiento desastroso, mal funcionamiento, usuarios descontentos: vamos a ver ahra unos puntos a tener en cuenta con el fin de mitigar estos riesgos y cómo SonarQube nos puede ayudar.
Divide y vencerás
Hemos visto que SonarQube permite una visión general de la aplicación, sobre todo en términos de indicadores cuantitativos, como el número de líneas de código (LOC), la Complejidad Ciclomática (CC), el nivel de los comentarios en el código, etc.
A continuación, hicimos un zoom sobre los componentes para identificar las funciones y los programas más complejos y los defectos que se encuentran en su código.
También hemos jugado con algunos widgets, incluyendo el Bubble Chart para cruzar algunos de estos indicadores entre sí o con la deuda técnica, y identificar los programas monstruosos que son el objetivo principal de nuestra reingeniería.
Figura 1 – Technical Debt x Cyclomatic Complexity/Function x Lines of Code
En la figura anterior, podemos notar inmediatamente el archivo ‘RTFOUT.C’ por el tamaño de su burbuja que representa la Ciclomática Complejidad (CC) promedio de las funciones de este programa. Pero el archivo ‘fltexp.c’ en la parte superior tiene la deuda técnica más alta, con un promedio de CC por función menos importante, simplemente porque tiene más funciones.
Un tal gráfico nos permite visualizar rapidamente los programas con un alto tamaño en líneas de código, con funciones complejas y una deuda técnica importante. Entonces podemos examinar cómo separarlos en varios componentes de menor granularidad para reducir la complejidad, mejorar su legibilidad y facilidar el futuro mantenimiento.
Vimos, por ejemplo, la función monstruosa del archivo ‘RTFOUT.C’ que se dedica a gestionar el formato de texto Rich Text Format de Microsoft. Los diferentes bloques de código se encargan de gestionar diferentes parmetros de fuentes, las propiedades del documento (autor, número de palabras o líneas, etc.) … Es muy fácil de especializar este código en diferentes funciones o clases.
Dos puntos importantes para esta redistribución funcional:
- Las pruebas unitarias: si ya tenemos, es probable que se necesitarán cambiar esos tests para adaptarlos a nuestro nuevo diseño. Si no tenemos, o si no son compatibles con el nuevo lenguaje, deben (re-)escribirse en el nuevo idioma.
- No es necesario reducir por completo la Complejidad Ciclomática (CC): se puede permitir tener algunos componentes complejos o muy complejos, pero no demasiado. Por ejemplo, una clase única para manejar todas las variables técnicas de la aplicación, con todos sus métodos (de hecho, muchos setters/getters sencillos) tendrá una CC proporcional a la cantidad de datos y métodos, pero en realidad será muy legible y fácil de mantener.
En este tema, nuestra reingeniería es en realidad un reverse-engineering que consiste en entender el diseño actual para repensarlo de manera diferente. A menudo es útil tener la ayuda de una herramienta de análisis de impacto para dibujar un mapa de los distintos módulos o paquetes y las relaciones entre ellos, identificar los vínculos entre las diferentes capas de aplicación (presentación, lógica, datos), visualizar los objetos más complejos, etc.
Una herramienta de análisis de impacto también será útil para identificar código muerto, es decir, los objetos (clase, método, tabla de base de datos, etc.) que no se utilizan, que no son llamados por cualquier otro componente. No hace falta volver a escribir componentes que ya no se utilizan.
Pero ten cuidado: estas herramientas con frecuencia producen falsos positivos y requieren buenas habilidades para su uso óptimo.
Código duplicado
Mientras SonarQube me enseña el código de funciones muy complejas, puedo tomar nota de los bloques de código duplicado. En la siguiente figura:
Figura 2 – Bloques de código duplicado en SonarQube
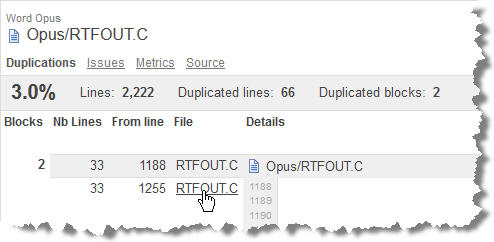
nos encontramos con dos bloques de 33 líneas copiadas/pegadas en las líneas 1188 y 1255 del mismo programa. En otros casos, estas duplicaciones se producirán entre diferentes archivos.
Es importante identificar el codígo duplicado temprano porque:
- A menudo son sinónimo de un diseño poco optimizado.
- Puedo evitar escribir el mismo bloque de código varias veces en el nuevo lenguaje.
- Reduzco el mantenimiento y los riesgos para la aplicación: cualquier cambio en el código duplicado se debe trasladar en cada una de las copias, lo que cuesta más en mantenimiento y aumenta el riesgo de defectos en caso de que se olvide una copia.
interfaz de usuario
Hemos visto que la interfaz de usuario podría ser en sí misma un objetivo de reingeniería. En este caso, es importante tenerlo en cuenta tan pronto como sea posible porque el cambio de pantallas puede tener un doble impacto:
- Modificación de los datos: en cuyo caso, tendremos que empezar con este paso y luego ver el impacto en términos de clases o programas o funciones.
- Modificación de los procesos de negocio: en este caso, trabajemos tan pronto como sea posible con los usuarios para validar estos cambios. Ni siquiera intentas comenzar la reingeniería antes de esta validación. Y sobre todo, no programar las pantallas de forma idéntica.
Cuidado de comprobar las operaciones que no son necesariamente programadas en la interfaz gráfica. Por ejemplo, todos los usuarios hacen Copiar/Pegar, y por lo general sin que se haya programado un botón o un menú para esto. Y el usuario rara vez evocará esto porque para él, es natural y obvio. Asegúrate de identificar estos procesos implícitos y hacer pruebas de que son reproducibles en la nueva versión de la aplicación, después de la reingeniería.
Compruebes la coherencia de los mensajes de usuarios: normalización o en torno a una frase con un verbo como «La cantidad no es correcta» o en torno a una expresión sin verbo: «error de entrada de la cantidad».
Echas un vistazo a las inconsistencias en las representaciones de datos, a veces con decimales, a veces sin, por ejemplo.
Seguiremos en el próximo post: veremos cómo estudiar la reestructuración de los tratamientos con SonarQube.
Esta entrada está disponible también en Lire cet article en français y Read that post in english.