
 We defined our reengineering project as rewriting our legacy application in a new language or migrating it to a new technology, as opposed to a refactoring which involves reorganizing the code and to correct certain defects in order to make it more maintainable and reduce its technical debt.
We defined our reengineering project as rewriting our legacy application in a new language or migrating it to a new technology, as opposed to a refactoring which involves reorganizing the code and to correct certain defects in order to make it more maintainable and reduce its technical debt.
We saw different plans of refactoring more or less ambitious, with the help of SonarQube and the SQALE plugin, from the resolution of the most critical defects to a reduction of the technical debt to a ‘A’ level (SQALE rating ) .
However, for the same Legacy application, is it more interesting to carry out a reengineering project or ‘just’ refactoring?
Most times, the investment for a reengineering will be higher, since it is rarely possible to modulate it, except in the case of a partial reengineering, just for the user interface for example, when a refactoring may be done over time in the medium or long term.
But we can assume that the benefits of reengineering will be much higher than those of a refactoring as the technical debt should, not disappear completely – there will always be complex objects or errors due to lack of attention – but at least be very strongly reduced.
This, if the reengineering project is a success, obviously.
Because the risks of failure are important:
- You do not master the new technology, the new platform or the targeted language, you lack knowledge or expertise in this area. Your new application has problems of performance.
- You miscalculated the reengineering effort, you have to develop quickly in a rush and forget to do unit tests to meet the deadlines of the project. Your new application is buggy.
- Some procedures or business processes are changed, under the excuse of making them more simple, but in fact to ease the workload. Your new application does not meet the business requirements and is more complex to use.
- You have not precisely identified the objectives, users are not incorporated into the project. You face many new requests on their part and you blow up your budget and schedule.
Disastrous performance, malfunctions, discontented users: let’s see some points to consider in order to mitigate these risks and how SonarQube can help us.
Divide and Conquer
We have seen that with SonarQube, we can get an overview of the application, particularly in terms of quantitative metrics such as the number of lines of code (LOC), the Cyclomatic Complexity (CC), the level of comments in the code, etc.
We then zoomed in on these components to list the most complex functions and programs and identify efects found in their code.
We also played with some widgets, including the Bubble Chart, in order to cross some of these metrics with the technical debt, and list the monstrous programs that are the primary target of our reengineering.
Figure 1 – Technical Debt x Cyclomatic Complexity/Function x Lines of Code
In the previous figure, we can see immediately the file ‘RTFOUT.C’, from the size of its bubble representing its average Cyclomatic Complexity (CC) by functions in this program. But the file ‘fltexp.c’ at the top has the highest technical debt, with an average CC by function less important, simply because it has more functions.
Such a graph allows us to visualize immediately programs with a high size in lines of code, with complex functions and a heavy technical debt. Then we can examine how to divide them in several components of smaller granularity in order to reduce their complexity, and improve their readability and maintainability.
For example, we have seen the monster fonction of the program ‘RTFOUT.C’ which deals with the Microsoft’s Rich Text Format (RTF). Different blocks of code manages settings for fonts (bold, italic, etc.), document properties (author, number of words or lines, etc.) … It is quite easy to specialize this code in different functions or classes specific to each of these treatments instead of having all of them in a unique program.
Two important points for this functional reallocation:
- Unit tests: if we already have unit tests, we will probably need to modify them in order to adapt them to our new design. If we do not have, or if they are not compatible with our new targeted language, we will have to port them into the new language.
- It is not necessary to target a zero Cyclomatic Complexity (CC). We can afford to have some very complex components, but not too much. For example, a single class that has to handle all the technical variables or constants, with all corresponding methods (in fact, many setters/getters) will have a CC proportional to the number of these methods, but in fact should remain very readable and maintainable.
Our reengineering here is actually closer to a reverse engineering which consists in understanding the current design in order to rethink it differently. It is often useful to have the assistance of a tool for doing impact analysis in order to draw a map of the various modules or packages and the relationships between them, identify links between different application layers (presentation, logic, data), view the most complex objects, etc.
An impact analysis tool will also be useful for identifying the dead code, ie. objects (class, method, database table, etc.) that are not used, which are not called by any other component. Needless to rewrite components that are no longer used.
But beware: these tools frequently produce false-positives and require good skills for optimal use.
Duplicated code
While SonarQube displays the code of these complex or very complex functions, I can make note of the duplicated code. In the following figure:
Figure 2 – Lines of blocks of code duplicated
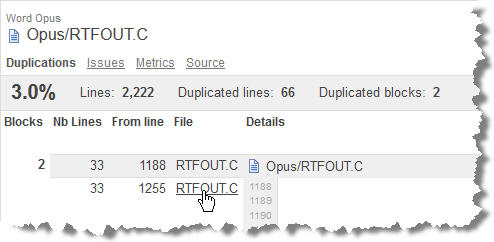
we can identify two blocks of 33 lines copied/pasted at the lines 1188 and 1255 of the program. In other cases, these duplications will occur between different files.
It is important to identify early because:
- They are often synonymous of a poorly optimized design.
- I can avoid rewriting the same block of code several times in the new language.
- I can reduce maintenance and risks for the application: any change in the duplicated code should be reported on each of the duplicated blocks, which cost more in maintenance and increases the risk of defects in case you forget.
User interface
We have seen that the user interface could be in itself an objective of reengineering. In this case, it is important to consider it as early as possible because changing screens can have a double impact:
- Modification of data: in which case you will need to start with this step and then look at the impact in terms of design, classes or programs or functions.
- Modification of business processes: in this case, work as soon as possible with users to validate these changes. Do not even try to start your reengineering before this validation. And especially not to program screens identically.
Be careful to check at users operations that are not necessarily encoded in the GUI. For example, all users do Copy/Paste, and generally you have not programmed a button or menu to do this. And user rarely evoke this because it is natural and obvious. Be sure to identify these implicit operations and test that they are reproducible in the new version of the application, after reengineering.
Check the consistency of user messages: normalizing them around a phrase such as ‘The amount entered is not correct’ or around an expression: ‘error of amount input’.
Check out the inconsistencies in the data representations, sometimes with decimals, sometimes without it.
To be continued in the next post: we will look at restructuring treatments and how SonarQube can help.
This post is also available in Leer este articulo en castellano and Lire cet article en français.