
 Suite de notre série sur l’analyse du code source de Word 1.1a, la première version de ce traitement de texte publié par Microsoft en 1990.
Suite de notre série sur l’analyse du code source de Word 1.1a, la première version de ce traitement de texte publié par Microsoft en 1990.
Dans le premier post, nous avons vu les métriques quantitatives de taille (LOCs), de complexité (CC), le niveau de commentaires et de duplication. Le second post était consacré aux différentes Issues’ de type Blocker, Critical, Major et Minor.
Ces résultats d’analyse semblent indiquer une stratégie de développement nettement orientée vers la fiabilité et la performance logicielle, puisque nous rencontrons peu de violations aux ‘best practices’ dans ce domaine. Celles-ci sont par contre beaucoup plus nombreuses en matière de lisibilité et de compréhension du code, et donc de maintenabilité.
Je rappelle que j’ai effectué cette analyse ‘brute de forme’ : j’ai résolu certains problèmes de parsing mais je n’ai pas cherché à déclarer les macros, et j’ai travaillé avec le Quality Profile (ensemble de règles) par défaut. L’important selon moi pour cette série n’est pas de rechercher la précision maximale dans les résultats, car l’objectif n’est pas d’effectuer un audit de code pour cette version de Word, mais de voir comment une simple évaluation et quelques indicateurs peuvent s’avérer utiles en fonction du contexte.
Cas d’utilisation
Qui dit contexte dit Use Cases. Lorsque l’on parle d’applications Legacy, les cas d’utilisation les plus fréquents seront :
- Outsourcing : transférer la maintenance de l’application à une nouvelle équipe, généralement une société de services, le plus souvent dans le but de réduire les charges de maintenance.
- Refactoring : la dette technique pour cette application a crû dans de telles proportions que toute modification du code présente un coût de changement excessivement élevé. Un refactoring est nécessaire afin de réduire les intérêts de la dette.
- Ré-ingénierie : un refactoring signifie très souvent de repenser le design, c’est-à-dire la conception voire l’architecture de l’application. Pourquoi ne pas en profiter pour réécrire cette application dans un autre langage, plus récent, moins difficile à maintenir ?
- Abandon : faut-il jeter cette application ? C’est une question qui se pose fréquemment pour une application Legacy, notamment dans le monde Cobol. S’il coûte moins cher de la remplacer par un progiciel, alors on s’en débarrasse.
Je vais maintenant me placer dans un contexte bien précis : vous avez décidé de racheter Microsoft. Oui je sais, c’est un peu difficile à imaginer mais faites un effort. Votre mission – si vous l’acceptez – est de recommander une stratégie concernant cette version de Word :
- Outsourcing : quel serait le coût pour transférer la connaissance de cette application à une autre équipe R&D ?
- Refactoring : quel serait le coût de résolution des actuels défauts rencontrés (re-design inclus), par l’équipe actuelle ? Ou par une nouvelle équipe, après transfert de connaissance (donc cas 1 + 2) ?
- Ré-écriture : porter cette application vers une nouvelle technologie, par exemple C++. Par la même équipe ou une nouvelle équipe, encore une fois après transfert de connaissances (donc cas 1 + 3).
- Abandon. Décision qui relève du management. On ne va pas remplacer l’application par un progiciel, mais si cela coûte plus cher de la maintenir que ce qu’elle rapporte, on laisse le software mourir de sa belle mort, avec un équipe réduite pour corriger les bugs les plus critiques, et sans travailler sur une évolution.
Afin d’évaluer les coûts de ces différentes stratégies, j’ai réfléchi aux différentes données et informations disponibles dans mon tableau de bord, et lesquelles prendre en compte pour chaque cas.
En commençant par l’estimation du coût de transfert de connaissance de cette application Legacy vers une nouvelle équipe. Qu’est ce qui fait qu’un programme ou une fonction sera plus ou moins difficile à comprendre ?
- Sa taille : plus un programme est long, plus il nécessite de temps pour savoir ce qu’il fait.
- Sa complexité : plus un programme comporte de conditions – simples tel qu’un if…else, ou multiples (switch) – et de boucles, plus il est difficile d’appréhender le flux des traitements.
- Sa structure : plus un programme comporte de blocs de code imbriqués, de goto, de break et autres instructions qui induisent une lecture non linéaire du code, plus les algorithmes sont compliqués.
Je me suis d’abord intéressé aux données dont je disposais sur la complexité.
Complexité
Fonctions
Nous avons vu dans le premier post que cette application comptait quelques fonctions et fichiers avec un nombre élevé de points de Cyclomatic Complexity. En fait, la répartition est la suivante :
Tableau 1 – Complexité Cyclomatique des fonctions de l’application Word Opus 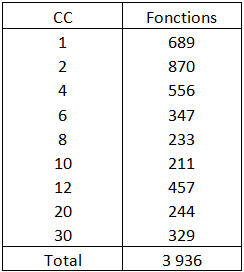
On compte 689 fonctions avec une Complexité Cyclomatique égale à 1, puis 870 fonctions avec une CC égale à 2 et inférieure à 4, etc.
On considère que la distribution optimale de la Complexité Cyclomatique d’une application C est comme suit :
- Fonctions peu complexes, avec une CC < 4 (Low) : 52% du nombre total de fonctions dans l’application.
- Fonctions moyennement complexes, avec une CC > 4 et < 10 (Moderate) : 25%.
- Fonctions complexes, avec une CC > 10 et < 20 (High) : 15%.
- Fonctions très complexes, avec une CC > 20 (Very High) : 8%.
Si l’on calcule la distribution de la complexité dans notre application Word, sur la base du tableau 1, nous obtenons la table suivante :
Tableau 2 – Distribution de la complexité dans l’application Word Opus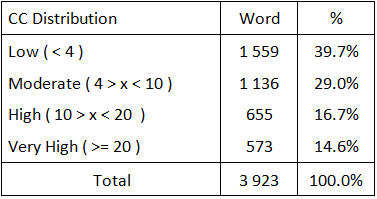
La figure suivante présente la courbe de distribution de la complexité dans Word, comparée à la courbe idéale.
Figure 1 – Courbe de distribution de la complexité (Fonctions) 
On s’aperçoit que la proportion de fonctions de complexité moyenne ou élevée est assez en ligne :
- 29 % de ‘Moderate’ dans Word contre 25% idéalement.
- 16.7 % de ‘High’ dans Word contre 15% idéalement.
Par contre, les fonctions peu complexes ne sont pas assez nombreuses : 39.7% au lieu de 52%. Et le niveau de fonctions très complexes est trop élevé : 14.6% contre 8% dans l’idéal. Cela devrait donc influer sur les coûts de transfert de connaissance ou de ré-engineering de cette application.
Je me suis ensuite intéressé aux fonctions les plus complexes, à l’aide de la métrique suivante qui nous donne la Complexité Cyclomatique des fonctions au-delà de 20 points de CC : ![]() A noter que nous avions recensé 573 fonctions avec une CC supérieure ou égale à 20, ce qui signifie que nous comptons 34 fonctions (573 – 539) à exactement 20 points.
A noter que nous avions recensé 573 fonctions avec une CC supérieure ou égale à 20, ce qui signifie que nous comptons 34 fonctions (573 – 539) à exactement 20 points.
Ces 539 fonctions représentent une Complexité Cyclomatique de 24 667, soit plus de la moitié de la CC totale de l’application (43 846, comme vu dans le premier post de cette série) et certaines fonctions sont extrêmement complexes :
Tableau 3 – Distribution des fonctions les plus complexes

Nous comptons :
- 6 fonctions au-delà de 200 points de CC (la plus importante atteint même les 355 points), pour un total de 1 513 points de CC. Donc ces 1% des 539 fonctions très complexes représentent 6% de la CC de toutes ces fonctions (1 513 / 24 667).
- 30 fonctions entre 100 et 200 points de CC, pour un total de 3 921 points, soit 5.6% des 539 fonctions très complexes et 15.9% de la CC globale de celles-ci.
Donc en résumé, 36 des fonctions au-delà de 20 points de CC représentent 22% de la complexité globale de ces 539 fonctions.
Si on regarde au niveau de l’ensemble de l’application, 36, c’est-à-dire 0.9% des 3936 fonctions existantes représentent 12.4% de la Complexité Cyclomatique totale (43 846 points).
Inutile de dire que nous porterons une attention toute particulière à ces objets, lorsque nous étudierons notre plan d’action, que ce soit pour un transfert de connaissances, un refactoring ou un re-engineering.
Nous continuerons cet article dans le prochain post, en effectuant ce même travail sur la complexité, au niveau des fichiers cette fois.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.