
 Nous avons vu dans le post précédent comment entamer un reengineering avec SonarQube en commençant par un redécoupage fonctionnel et le re-design de notre application.
Nous avons vu dans le post précédent comment entamer un reengineering avec SonarQube en commençant par un redécoupage fonctionnel et le re-design de notre application.
Nous pouvons maintenant descendre un peu plus dans le code afin d’identifier des flux de traitements candidats à restructuration.
Restructuration des traitements
Je vais à nouveau utiliser le SQALE Sunburst afin de naviguer entre les différentes violations aux best practices de programmation et rechercher tout indice de ‘code spaghetti’.
Figure 1 – Refactoring de ‘goto’
 Ce widget me permet de chiffrer l’effort de refactoring – 158.8 jours – afin de corriger ces ruptures de flux de traitements et ces algorithmes qui sautent dans tous les sens.
Ce widget me permet de chiffrer l’effort de refactoring – 158.8 jours – afin de corriger ces ruptures de flux de traitements et ces algorithmes qui sautent dans tous les sens.
Je peux faire de même pour chacun des défauts de ce type, par exemple l’utilisation de ‘continue’. Un click m’amène ensuite à la liste des programmes comportant ces violations :
Figure 2 – Liste de violations ‘continue’ 
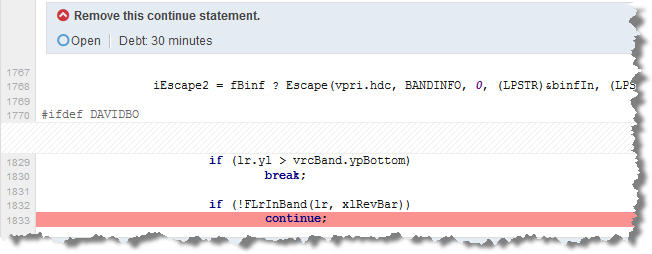
De là, je peux descendre dans chaque programme et vérifier ce code, pour chaque ligne comportant une de ces violations. Dans la figure suivante, nous pouvons voir une ligne de code avec une instruction ‘continue’, ainsi que le ‘break’ qui l’accompagne, et l’estimation – 30 minutes – de dette technique pour résoudre ce code spaghetti.
Figure 3 – Ligne de code avec violation et évaluation de la charge de résolution
Nous pouvons voir à travers cet exemple comment utiliser SonarQube afin d’aller directement à l’essentiel :
- Une estimation générale de charge de refactoring des flux de traitement, à travers le plugin SQALE.
- Une estimation plus fine, au moins pour les composants ‘monster’ les plus complexes qui vont peser le plus sur la charge globale de réingénierie.
L’équipe de projet peut descendre dans chaque programme, comme nous l’avons fait dans cet exemple, pour évaluer le niveau de déstructuration du code et réécrire celui-ci en respectant la logique fonctionnelle, mais en modifiant la logique algorithmique. La solution aux ‘goto’, ‘break’ et ‘continue’ est simple : utiliser des ‘if..else’. Attention cependant à ne pas trop imbriquer ceux-ci.
Chaque langage aura ses propres particularités en matière de flux de traitements, et les bad practices dans ce domaine seront différentes en C, en Cobol, en ABAP. L’important est de bien prendre en compte ce point, et nous avons vu comment SonarQube pouvait nous y aider.
Restructuration des données
Un reengineering des traitements s’accompagne bien souvent d’un reengineering des données. Tout un sujet en lui-même, on pourrait écrire un livre entier sur ce seul thème. Rapidement, quelques pistes de recherche qui me viennent à l’esprit :
- Vérifiez si l’application utilise des fichiers, et s’il serait envisageable de les transformer en tables. Lorsque les données sont temporaires, un log de messages par exemple, on a tendance à les mettre en fichiers. Pourtant, on peut se poser la question de stocker cette information en base de données, car un ‘Insert’ dans une table est (normalement) plus rapide que l’écriture d’une ligne dans un fichier. Et dans les deux cas, il faudra bien vider celui-ci ou la table en base de données, lorsque son volume devient trop important.
- Identifiez les données dont les caractéristiques de type, de taille ou de précision vous paraissent singulières, inhabituelles, bref bizarres. Valider celles-ci avec les utilisateurs et en profiter pour leur demander s’ils ont des requêtes dans ce sens.
- Vérifier s’il existe des structures de données partagées, quels composants utilisent les mêmes tables ou fichiers. Dans ce cas, il est important de tenter de spécialiser les composants car des accès multiples sur une table sont une source importante de bugs et de coûts plus importants de maintenance. J’ai vu des applications où une même table était accédée en Insert/Update/Delete par plus de 80 classes différentes. Chaque fois qu’un développeur avait besoin de réaliser un traitement sur cette table, il programmait ses propres requêtes SQL, sans vérifier s’il n’existait pas déjà une méthode qui faisait ce même traitement. Résultat : toute modification de la structure de la table nécessitait de vérifier et éventuellement de modifier toutes ces classes. Vous imaginez l’investissement nécessaire pour cette tâche et le niveau de risque si l’on oublie une de ces méthodes !
- Et pendant que vous y êtes, vérifiez qu’il n’existe pas de données redondantes.
- Même chose pour les inconsistances de données : un écran qui affiche une mesure en km et un autre en mètres, ou en jours et en heures, ou en heures et en minutes, etc.
- En profiter pour aller voir les défauts au niveau SQL dans le code. Pourquoi ces ‘select *’, ‘select … into select’, ces JOIN imbriqués ou sur de multiples tables, etc. Nous avions vu bon nombre de ces ‘Issues’ dans notre série sur l’analyse de code PL/SQL avec SonarQube.
Si vous avez des tables temporaires construites en dynamique durant une session utilisateur, ceci implique généralement des traitements très complexes qu’il n’est pas possible de régler par de ‘simples’ curseurs ou boucles, comme du calcul d’agrégation statistique. Vérifiez avec les utilisateurs la criticité de ces traitements. On ne peut pas avoir une même application qui présente la fiche d’un client à l’écran en moins d’une seconde et en même temps effectue dynamiquement une corrélation sur toutes sortes de statistiques. Ce sont deux applications différentes, l’une classique de gestion, l’autre de reporting ou d’infocentre.
Autres points
Vérifiez si l’application originale était correctement commentée et viser à garder au moins ce niveau de documentation, voire à l’améliorer si ce n’est pas le cas.
Règles de nommage: si elles n’existent pas, c’est le moment de les fixer pour les développements futurs avec ce nouveau langage. Si elles existent, veiller à les mettre à jour, mais en s’appuyant sur les standards en vigueur, ce qui signifie également de vérifier vos choix avec les autres équipes de projet, et s’assurer que tout le monde utilise les mêmes normes.
Utiliser un outil d’analyse de code afin de vérifier – très – régulièrement que vous n’introduisez pas des violations aux bonnes pratiques dans le nouveau langage, qui ne sont pas forcément celles du langage précédent. Ok, nombre de défauts en C existent en C++ mais l’inverse n’est pas vrai.
Et surtout, prenez en compte les tests unitaires. Nous avions déjà fait une estimation de la charge et des plans d’action possibles dans ce domaine.
Conclusion
Nous n’avons pas listé toutes les pistes possibles d’actions de réingénierie, vous pouvez en imaginer bien d’autres. En fait, cela sera très dépendant du projet, de l’application, de la technologie cible, … Il n’a pas de démarche type qui assure invariablement le succès du projet, mais il y a de bonnes chances que les points listés ci-dessus améliorent les chances de réussite de votre réingénierie.
Un dernier conseil, pensez à l’avenir: le portage des applications dans le Cloud (donc découplage de certains types de traitements, APIs RESTfull, stateless/statefull, etc.).
D’ailleurs, je pense que nous allons bientôt voir de plus en plus de projet de réingénierie d’applications dans le but de porter celles-ci dans le Cloud.
Ceci clôt cette longue série sur le refactoring et le reengineering d’une application Legacy. Pour les prochains posts, je pense upgrader mon installation SonarQube et voir ce qui a changé en matière de code Cobol et SAP.
A bientôt.
Cette publication est également disponible en Leer este articulo en castellano : liste des langues séparées par une virgule, Read that post in english : dernière langue.