
 Microsoft has released this week the source code of Word 1.1a (1990) to the Computer History Museum: http://www.computerhistory.org/atchm/microsoft-word-for-windows-1-1a-source-code/.
Microsoft has released this week the source code of Word 1.1a (1990) to the Computer History Museum: http://www.computerhistory.org/atchm/microsoft-word-for-windows-1-1a-source-code/.
This is an early version of Word for Windows, January 1991:
http://blogs.technet.com/b/microsoft_blog/archive/2014/03/25/microsoft-makes-source-code-for-ms-dos-and-word-for-windows-available-to-public.aspx.
I was interested in analyzing the source code of this release. I was curious to see what would be the results from both a quantitative point of view – number of lines of code, complexity , etc. – and a qualitative one: violations of best programming practices, Blockers, Critical defects, etc.
Also, how to use technical debt in such a context? It is not every day that we have such a Legacy C application. What are the interesting use cases in this context and how the analysis of the technical debt can help us?
I will come back to this point later. I still do not know how many posts I’ll do on these topics. In this first article, I will briefly present the configuration of the analysis and the first results
Analysis
I will not go into much details, because this source code is not published under a free license and it is forbidden to use it for commercial purposes. You understand that I do not have any desire to get in trouble with Microsoft if I begin to highlight a company or its products. So I would just say that I did my analysis with SonarQube version 4.2 and its plugin C/C++ version 2.1.
 If you download the .zip file corresponding to Word 1.1a’s source code, you will encounter three directories corresponding to various versions, with some documentation or utilities. I used the simplest version, ‘Opus’, which focuses on the source code.
If you download the .zip file corresponding to Word 1.1a’s source code, you will encounter three directories corresponding to various versions, with some documentation or utilities. I used the simplest version, ‘Opus’, which focuses on the source code.
There are several types of files that cannot be analyzed, as .exe utilities or assembler code. I did work only with .c and .h files. The folders ‘lib’ and ‘resource’ contains only .h. Other directories, including the main one ‘Opus’, have a mix of .c and .h files.
I have not tried to declare macros. This requires a precise knowledge of the application, and without working with an architect or a member of the project team, it would take a long time to understand how all the code is structured. I know this would be essential to identify potential bugs, but I do not seek such precision in the results, rather a general assessment of the quality of this application.
I met some parsing errors, mainly caused by declarations of a specific type, for a compilation on Mac I think. I tried various types of C syntax (C89 , C99 or C11), but for the same results. These are essentially data structures that I commented out with no impact on the results of the analysis, except that I will have a few less lines of code in the final calculation.
There are also files not to be scanned, such as a file that starts with ‘THIS FILE IS OBSOLETE’, and this line is not even commented out, so it is normal that it generates an error for the parser.
Finally, I did use the default Quality Profile for C, without using additional rules such as those of Cppcheck. Again, our goal is not to debug Word, but to get a comprehensive view of the code quality, evaluate the technical debt for this software and try to think what we can learn from it. All in the context of this time, more than 30 years ago.
Quantitatives metrics
I call quantitative metrics all results that give us an indication of the size and complexity of the code, the documentation, etc. In short, everything that does not relate to good programming practices.
Size
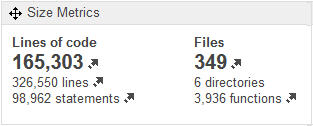 There are 326,500 lines in 349 files, of which 165 thousand are lines of code (KLocs). I expected to find many more lines of code, but I was surprised by the small number of files.
There are 326,500 lines in 349 files, of which 165 thousand are lines of code (KLocs). I expected to find many more lines of code, but I was surprised by the small number of files.
On average, each file has nearly 1 000 lines, half of which are lines of code. This does not encourage reading and understanding it, especially when it is a complex language as C language.
Moreover, if we look at the distribution of the code files, using the Project File Bubble Chart, we can see some nice monsters, as this file ‘ fltexp.c ‘ which has 2 600 lines of code and 506 issues. Note however that its technical debt remains limited with only 23 days of refactoring estimated to correct the defects.

Documentation
The level of comments is correct without being exceptional, I would say in the lower range of what can generally be expected in such an application today, but again, we are not in the presence of a traditional application, but of a software.

In addition, the level of documentation is important when you know that an application can be outsourced, and others than its authors will have to understand what does the code, which is not the case for R&D team. Finally, 20% of comments was probably correct 30 years ago, even if it seems rather low today.
Duplications
I was surprised by the minimum level of duplications. And going to check in the code, it could see these are essentially data structures.
Remember that we are not dealing here with an object oriented language, so it is not possible to create classes specific to a functional entity. Even so, the extremely low level of duplication shows an optimal reuse of existing code. Probably essential for an R&D that must develop and maintain software, but certainly not so common these days.
Complexity
 The overall level of Cyclomatic Complexity is quite high, with 43,846 points of complexity. Remember that at 20.000 points, an application requires a specific QA phase, with formalized tests.
The overall level of Cyclomatic Complexity is quite high, with 43,846 points of complexity. Remember that at 20.000 points, an application requires a specific QA phase, with formalized tests.
Above 60,000, a testing automation tool is highly recommended. Such tools did not exist in the early 1990s, so I’m curious to know more about Microsoft’s practices at this time.
The vast majority of the functions are not very complex, but however several hundred are above 12 points of CC, and a large number are exceeding 30 points, so are complex or very complex objects, with a high cost of maintainability and a high risk of introducing a defect in case of change. The QA phase must therefore be even more rigorous.
Fortunately, we have seen a pretty good level of reusability. We can therefore focus regression tests on the most complex objects that have been modified, as the other ones have already been validated before.
 This high level of complexity is confirmed at file level, with about half of them beyond 90 points of CC.
This high level of complexity is confirmed at file level, with about half of them beyond 90 points of CC.
I set the Bubble Chart to cross the number of lines of code with the Cyclomatic Complexity.

Once again, the file ‘fltexp.c’ is ahead with 2.600 lines of code and a 740 of CC. I told you this is a monster!
Evaluation
What can we say at this stage of our evaluation?
The very low level of duplicated code makes me think that the choice of architecture made by the team focused on a maximum reuse of existing functions, and thus be able to dedicate each file to a specific feature, with all the objects necessary to manage it. This explains why some files are very impressive, both in size and complexity.
We must remember that the memory was limited at that time, and the size taken by a software in memory was a decisive criterion of performance and thus of the success or failure of this soft. So efficiency in this domain was a top priority, which means to avoid duplicating the same data structure in different files, even if it means longer, heavier, more complex files.
This will probably affect the readability, understandibility and maintainability of the code.
We will pay attention to these factors in our assessment, starting with our next post on qualitative metrics and compliance with good programming practices.
This post is also available in Leer este articulo en castellano and Lire cet article en français.